
Introduction
Reading and writing is the most basic functionality that Pravega offers. Applications ingest data by writing to one or more Pravega streams and consume data by reading data from one or more streams. To implement applications correctly with Pravega, however, it is crucial that the developer is aware of some additional functionality that complements the core write and read calls. For example, writes can be transactional, and readers are organized into groups.
In this post, we cover some basic concepts and functionality that a developer must be aware when developing an application with Pravega, focusing on reads and writes. We encourage the reader to additionally check the Pravega documentation site under the section “Developing Pravega Applications” for some code snippets and more detail.
Writing to a stream
The API we currently expose for writing enables applications to append events to a stream. Event is an application concept, and it is up to the application to define what an event is and what it represents. As far as the core of Pravega is concerned, events are sequences of bytes, and Pravega does not try to make sense of events. We expect the application to pass a serializer that enables Pravega to take events of arbitrary types and transform them into byte sequences. Ultimately, Pravega stores sequences of bytes in stream segments, and it is not aware of event types.
Storing sequences of bytes rather than events enables Pravega to support abstractions other than events in the API, e.g., we plan to expose calls to read and write byte streams. This feature will be useful when an application has other large objects containing immutable data to store, say checkpoints in Apache Flink. With such an API, the application is able to store these objects directly in Pravega rather than relying on a separate store.
Recall that a Pravega stream is composed of segments and any given stream can have many parallel segments open at any point in time. To map events to segments, the application passes a routing key along with the event itself.
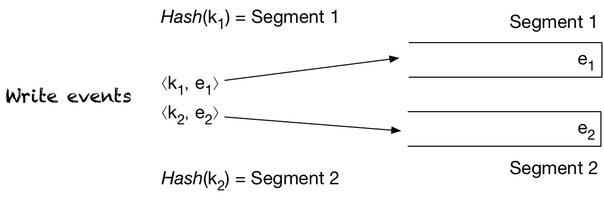
The routing key is a string that is hashed to determine which segment the event is to be appended to. Pravega guarantees that the assignment of routing key to segment is consistent. Note that the mapping of routing key to segment is not always the same because of stream scaling, but it is consistent. Between two scaling events, all events written to a stream with the same routing key are mapped to the same segment. Segments across scaling events are ordered according to the scaling. To make it concrete, say for the sake of example that we scale up from one segment S1 to segments S2 and S3. The key space of S1 overlaps with the ones of S2 and S3, but S2 and S3 have no intersection, so it is fine to append to S2 and S3 concurrently, but not to append to say S1 and S2 concurrently because events with the same routing key can go to two different segments. To prevent the latter case from occurring, no append happens to S2 and S3 until S1 is sealed, and this generalizes to any number of segments before and after a scaling event. Consequently, once segments are sealed due to a scaling event, future events are appended to the successors of the sealed segments, preserving routing key order.
Writing events to a stream is simple, with two options: regular and transactional. With regular writes, the writer can simply fire away calls to write events:
With transactions, the writer begins a transaction and makes as many calls to write an event as it wants:
Once it is done, it commits the transaction, which makes the writes in the transaction available for reading. The application can also choose to abort the transaction, in which case, the events written as part of the transaction are not made visible.
There are a couple of very interesting points about writers that are worth mentioning: duplicates and segment order.
Avoiding duplicates
Duplicates in a stream can be problematic: they can induce incorrect results or incorrect behavior in general. For example, a duplicate can lead to an incorrect count of instances or an incorrect transition in a state machine. Some applications are highly sensitive to such a deviation.
To avoid duplicates, writers internally have an ID that they use to determine the last event written upon a reconnection. When the writer has events to append, it initiates the write of a block of events. Once finished appending the block, the writer sends a block end command with the number of events written and the last event number. The writer appends in blocks to be able to benefit from batching.
The segment store must remember the last event number for any given writer ID. Otherwise, it cannot spot duplicates. To remember the last event number for a given writer ID, it persists the ⟨writer ID, event number⟩ pair as an attribute of the segment as part of processing the append request. In the case the writer disconnects and creates a new connection, the segment store fetches this attribute and returns the last event number written as part of the handshake with the client. This response from the segment store enables the writer to resume from the correct event in the case it had appends outstanding.
The writer does not persist or even expose its writer ID, however. If the writer crashes and a new one is instantiated, then the new writer will use a new writer ID. To avoid duplicates despite writer crashes, we need to combine this writer ID deduplication with transactions. With transactional writes, if the writer crashes before committing a batch of writes, then it can let the transaction timeout and abort, in which case a new writer can resume from the last commit point that the previous writer left off.
To sum up, Pravega avoids duplicates while writing by checking the event number associated with writer IDs and by using transactional writes to tolerate writer crashes. In the case a writer crashes in the middle of a transaction, the application can simply let the transaction time out and abort. The partial writes of such a transaction are not exposed to readers.
Segment order
Stream scaling causes the number of segments of a stream to change over time. Changes to the number of segments for a stream induces changes to the mapping of routing key ranges to segments over time. But, if the mapping changes, how do we guarantee that readers receive events with the same routing key following the order of appends?
To guarantee the order of events with the same routing key, the client works with the controller to read segments according to the order in which they have been created. For example, say that a stream starts with one segment that we call S1. At time T1, segment S1 splits into S2 and S3. Consequently, as part of scaling the stream, we split the key range of S1 between S2 and S3. To make the discussion simple, let’s say that we split it equally, so S2 ends up with [0.0, 0.5), while S3 ends up with [0.5, 1.0). To guarantee that all events with the same routing key can be read in append order, we need to make sure that a writer cannot append to either S2 or S3 before S1 is sealed. This is, in fact, precisely how the writer operates: when it finds a segment sealed, it asks the controller for the successors. In this example, when it hits the end of S1 (return code indicating segment sealed), the writer asks the controller and receives a response that S2 and S3 are the successors. The following figure illustrates this scenario:
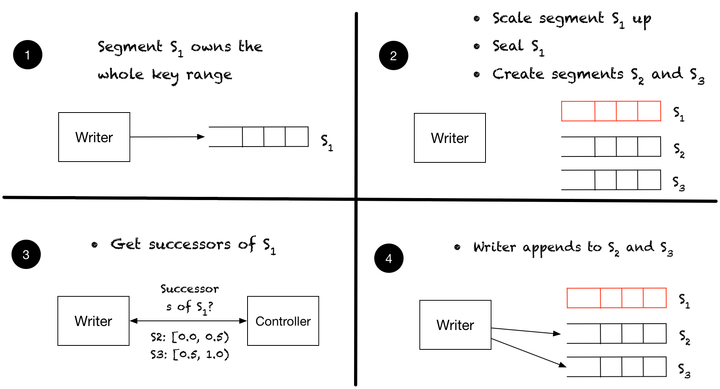
On the reader side, we have to also follow the order of segments, and we discuss it in more detail next when we present readers and reader groups.
Reading from a stream
A stream can have multiple segments that writers can append to in parallel. This parallelism is significant not only to enable higher ingestion capacity but also to enable parallelism when reading and processing events.
When appending events to a stream, we can have many writers accessing all segments of the stream concurrently. Writers are independent from each other and process events without any further coordination. We can have many readers on the reading side too, but readers are different, though. Typically, events need to be processed only once and consequently a group of readers need to coordinate the distribution of the workload of segments to split it across the group.
To enable readers to share the workload of one or more streams effectively, we use the concept of reader groups:
Reader group: A reader group is a set RG of Pravega readers and an associated set of streams S, such that, for each r ∈ RG, s(r) ⊆ ⋃ s∈S c(s) . At any time and for any two distinct readers r, r’ ∈ RG, s(r) ∩ s(r’) is empty.
In this definition, s(r) is the set of segments assigned to reader r, and c(s) is the current set of active segments of a stream (non-sealed segments enabled for reading). Note that this definition does not imply that all segments in ⋃ s∈S c(s) are assigned to some reader at any time. It is possible that a reader has released a segment while no other has acquired it yet or some new segment has not been acquired by anyone yet. The contract of the reader group is that any segment in ⋃ s∈S c(s) is eventually assigned. As such, the reader group does not guarantee that at any time ⋃ s∈S c(s) = ⋃ r∈RG s(r), although we do guarantee for liveness that for all x ∈ ⋃ s∈S c(s), eventually x is assigned to some reader.
Every reader must belong to a reader group. The following code snippet illustrates how to set up a reader:
The assignment of segments to readers in the group depends on the distributed coordination of readers using a mechanism we expose in Pravega called state synchronizer. The state synchronizer enables readers to have a consistent view of a distributed state, which they use to agree on changes to the state of the group, e.g., which segments are assigned and to which readers. The specific heuristic we use to determine the assignment is a simple one, but we leave a detailed discussion for another post.
There are four aspects of readers and groups that are worth highlighting.
Segment order
To guarantee that readers read events with the same key in append order, the readers follow a similar procedure as the writers. When a reader in a reader group encounters a sealed segment, it fetches the successors so that the group can read from such segments. If the successors correspond to the result of splitting the sealed segment, then readers can start reading from the successors right away. The following diagram illustrates this case:
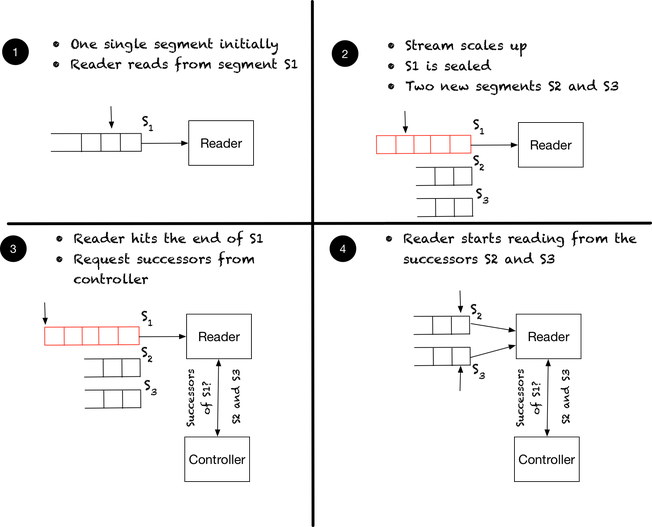
Initially, the stream has a single segment S1, and it eventually scales up, resulting in S1 splitting into S2 and S3. Once the reader hits the end of S1, it requests the successors from the controller, and it starts reading from the new segments.
But, what if the sealed segment has actually merged with another segment and this other segment has not been read entirely? Let’s make this aspect more concrete with an example.
Say that we have a reader group G with two readers, R1 and R2. The scenario is the following:
- Group G is reading a stream that has currently two segments S1 and S2.
- R1 is reading S1, while R2 is reading S2.
- The segments merge into S3 (S1 and S2 are sealed, they accept no further appends).
- Reader R1 hits the end of S1 and request its successors.
- Reader R1 gets back that S3 is the successor of S1.
- Reader R2 is not yet done with S2.
If either R1 or R2 proceeds to read S3 before R2 finishes reading S2, then we could be breaking our promise of reading events with the same key in append order. Consequently, to satisfy our order property, we put S3 on hold until R2 flags that it is done with S2. Only then S3 can be assigned and read.
To coordinate the assignments and order of segments, we again rely on the state synchronizer. When a reader obtains the successors of a segment, it updates the state accordingly, and this state will be synchronized across the reader group. Specific to the example, reader R1 adds segment S3 to the list of future segments, and the segment will be assigned only once all predecessors of S2 have been entirely read.
Checkpointing
We currently do not expose any segment information to the application via the reader group API. This is intentional. To guarantee that reads of a stream follow the correct order, we opted for hiding the complexity of successors, predecessors, and future segments from the application. Even though the application does not see segments explicitly, it still needs some way to determine a point in the stream that is consistent across all active segments and enables the application to resume from this point. For example, if the application wants to restart and resume from an earlier point in the stream, it needs a mechanism to refer to this earlier point.
Checkpointing is a mechanism we provide to enable an application to request an object that contains an offset for each segment that is currently being read or is available for reading. Checkpointing is implemented internally with the state synchronizer. Once triggered, the readers coordinate to produce an opaque checkpoint object that contains an offset for each segment that is currently being read or is available for reading.
Each reader records its current position for its assigned segments to the state once:
- It learns that there is a checkpoint going on;
- It has delivered a checkpoint event.
The checkpoint event informs the application via the reader that a checkpoint is in progress and the application is supposed to take any appropriate steps if any. For example, as part of checkpointing its state, the application might need to obtain the position of its input (the Pravega stream), to collect any local state for each process executing a reader, and to flush output downstream. Consequently, the application might want to react to the checkpoint event by collecting any state checkpointing information and flushing any output downstream to avoid duplicates.
We also use the opportunity of a checkpoint to rebalance the assignment of segments if at all needed. It is necessary to do it at checkpoint time to give the application the chance to flush any pending state changes, messages, events to avoid any duplication.
Failures and duplicates downstream
Reader groups enable a set of readers to read from a stream collectively. The reader group logic distributes the segments across the readers, in a manner that attempts to keep the load balanced.
One important question to ask is what happens when a reader crashes. Specifically, what happens to the segments assigned to that reader? Clearly, to make progress with these segments, we need to reassign them to a new reader. When reassigning these segments, we need to resume from some offset. Ideally, this offset is the first offset not read by the previous reader. Starting from the first segment offset (offset zero) is likely to lead to duplicate processing of events. If the application is sensitive to duplicates, then this is undesirable.
To enable applications to avoid duplicates when reading from Pravega, we do the following. With each event that the application reads, we provide a position object. The position object is a serializable, opaque object that contains the offsets of the segments the reader currently has assigned. This objectis similar to the checkpoint object, but scoped down to a single reader. The reader is supposed to persist this object as part of processing an event. If the reader crashes, Pravega expects the application to make the reader offline by calling a method of the reader group API and passing the last position object of the reader. This position object determines the position in the assigned segments the remaining readers need to start from.
We have opted, thus far, to push the crash detection to the application. The reader group API provides a readerOffline call, but it does not provide any mechanism to detect a crash. The application, consequently, needs to provide the detection and make calls to readerOffline accordingly.
Note that there is no magic behind the use of position objects. We require the application to cooperate: it is entirely up to the application to persist such position objects and retrieve the latest once a reader crashes. If the cost of maintaining such objects is high or undesirable, then the application risks having duplicates in its output depending on the nature of the processing performed.
Batch reads
There are times in which an application wants to simply process all events stored in a stream independent of order. Say, for example, that an application wants to collect all user ids in a stream, grep for words in events, or even perform a classic word count. The order of segments in such cases is not important.
For such cases, we expose a batch API that enables an application to take advantage of parallelism and iterate over the segments of a stream in any order and using any degree of parallelism that it desires.
To perform a batch read, an application requests an iterator over the segments:
And once it has this iterator, it can proceed to iterate over the segments individually:
If the application chooses to, it can read from all segments in parallel. Note that this API is, at the time of writing, experimental and subject to changes.
Wrapping up
Here we have covered some basic and not so basic concepts around ingesting and reading from Pravega. These are the main concepts one needs to understand to start coding against Pravega. The basic functionality is easy to use and understand, but there are clearly some nuances in the properties that we expose, with respect to order and duplicates, that are important for the developer to be aware of. For further detail, we recommend the reader to check both the website documentation and the code repository. We are also available on slack for questions.
Acknowledgements
Many thanks to Srikanth Satya, Matt Hausmann, Ken Steinfeldt for all the suggestions that have made this post substantially better.