
Traditional cache solutions treat each entry as an immutable blob of data, which poses problems for the append-heavy ingestion workloads that are common in Pravega. Each Event appended to a Stream would either require its own cache entry or need an expensive read-modify-write operation to be included in the Cache. To enable high-performance ingestion of events, big or small, while also providing near-real-time tail reads and high-throughput historical reads, Pravega needs a specialized cache that can natively support the types of workloads that are prevalent in Streaming Storage Systems.
The Streaming Cache, introduced in Pravega with release 0.7, has been designed from the ground up with streaming data in mind and optimizes for appends while organizing the data in a layout that makes eviction and disk spilling easy.
Not all caches are created equal. It is essential to choose a cache that fits the requirements of the system where it will be used, and streaming solutions are no exception to that rule. In this blog post, we describe an innovative way to look at caching that works well with streaming use cases.
How does the Segment Store cache data?
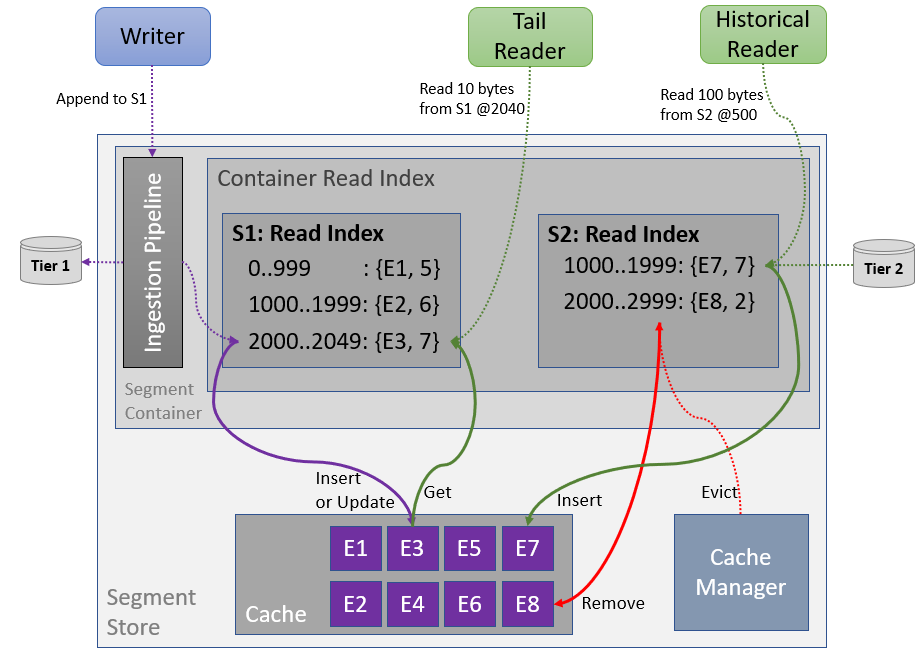
The Segment Store is at the core of all the data path operations in Pravega. It handles the ingestion of all events, enables near-real-time tail reads and is also responsible with providing high-throughput historical reads. All data going through the Segment Store are eventually routed through the Read Index, which provides a unified view of data stored in Tier 1 and Tier 2. On the append path, Events are persisted to Tier 1 and then added to the Read Index. Tail reads are served exclusively from the Cache, while historical reads are prefetched from Tier 2 and staged in the Read Index as necessary. The The Read Index’s dual purpose is to serve all read requests from EventStreamReaders and as a data source for moving data to Tier 2. As such, due to the sheer number of operations, it must be able to concurrently handle a significant number of updates and queries using as little CPU or memory as possible.
Each active Stream Segment has its Read Index, which is nothing more than a custom, in-memory AVL Tree mapping Segment offsets to cache entries. We needed a sorted index to help locate entries that contain, but do not begin with, a sought offset, and a balanced tree to keep insert and lookup times reasonably constant.
Why not a traditional cache?
At a minimum, the Read Index needs a cache that supports insertion, retrieval and removal. An intuitive choice for such a cache would be one that supports a traditional key-value API. This is precisely what Pravega has used until Version 0.7. Each Read Index entry was pointing to exactly one cache entry made up of a key and a value. While functioning correctly, such a cache implementation does not perform well under load for the segment store, introducing a bottleneck to the system.
A very common operation in streaming is appending data to a segment. Ideally, we would like to update our Read Index by appending the event bytes at the end of the last cache entry instead of having to create a new one for each append. However, Read Index Entries are mapped one-to-one to cache entries, and if the Cache does not allow for modifications of existing entries (immutability simplifies a lot of scenarios), there is very little we can do here. Our only two options for appends are either to create a new entry or perform an expensive read-modify-write operation each time (read last entry contents, allocate a new buffer with the existing contents and the append, then insert the new buffer back into the cache). Both have side effects resulting in excessive memory or CPU overhead, neither of which is desirable in high-performance systems.
Each key-value Cache needs to implement some sort of index to map keys to values. Whether a simple hash table for in-memory caches or a more sophisticated approach involving B+Trees or LSM Trees for disk-spillable caches, there is always a non-zero overhead for maintaining that index. However, if we step back and look at the Read Index, we observe we don’t need those additional data structures: the AVL Tree already maps segment offsets to cache entries. There is no need to maintain an additional index from our cache entries to whatever the Cache has internally. A simple (memory) pointer would suffice.
RocksDB was our initial choice for caching when we released Pravega for the first time. Although it makes an excellent local key-value store providing numerous features, Pravega didn’t use many of them and only used RocksDB as an off-heap cache that can spill over data to disk if necessary. However, while benchmarking Pravega in a containerized environment, we found several issues that were directly attributable to using RocksDB as a cache. The most important one was the inability to set a clear upper bound on the memory used, which caused Kubernetes to kill our pods due to excessive memory usage. The only way to control memory used by RocksDB is by configuring the write and read buffer sizes. Increasing the write and read buffer sizes allows more data to be cached in memory before a disk-based compaction is required while decreasing them triggers more frequent compactions, which in turn leads to more frequent and longer write stalls causing performance to degrade. To avoid being bound by a physical drive, one has the option of running RocksDB with an in-memory storage, but using that option made it even harder to control the total memory used. Even with WAL originally disabled (we did not require recovery after a crash), we tried tuning all available RocksDB parameters, which included disabling bloom filters and tweaking the compaction stile, but observed no noticeable effect, so we decided to look for an alternate implementation to this core component of our system.
As part of Pravega Version 0.7, we wanted to improve the system’s performance and spent numerous hours identifying and resolving bottlenecks on the ingestion path. Core to those improvements was the Streaming Cache: an innovative approach to caching from the streaming perspective.
Designing the Streaming Cache
We wanted to keep our cache data off-heap to avoid Java Garbage Collector issues. While this helps us avoid those dreaded GC pauses, it also means we cannot take advantage of a key benefit that it provides: memory compaction. Memory allocators need to find a contiguous block of memory (of the requested size) when invoked, so arbitrarily storing and deleting arrays of varying sizes will eventually lead to out-of-memory errors. Java’s GC moves the heap objects around to reduce fragmentation, but we won’t be able to use it for our purpose. We, therefore, need a design that reduces or eliminates this problem with minimal overhead.
Running Pravega in a containerized environment such a Kubernetes requires proper tuning of its memory consumption. Since the Cache is part of this memory, we must keep an upper bound on the memory utilization of the Cache, including its metadata/indexing overhead. Any cache is prone to have such overheads: even a simple hash table needs to store both keys and values, as well as any extra unused array cells. During our extensive testing of Pravega in such an environment, we have found it quite difficult to contain the cache memory consumption using available open-source options.
To solve both memory fragmentation and metadata overhead, we took inspiration from block storage. We divide our Cache into equal-sized Cache Blocks, where each such block is uniquely addressable using a 32-bit pointer—choosing a block length of 4KB yields a maximum theoretical capacity of 16TB per Cache, which is more than enough for a single-node cache.
Cache Blocks are daisy-chained together to form Cache Entries. Each Cache Block has a pointer to the block immediately before it in the chain. Since each block has an address, we can choose the address of the last block in the chain to be the address of the entry itself. We can then reference this address from the Read Index. While a bit counter-intuitive, pointing to the last block enables us to immediately locate that and perform appends, by either writing directly to it (if it still has capacity) or find a new empty block and add that to the chain.
Similarly to the blocks used in cache entries, empty cache blocks are also chained together, which makes locating an available block an O(1) operation. All we need to do when allocating a new Cache Block is to find the one at the head of this list, which would make its successor the next head. Deleting an entry would cause its cache blocks to be added back to this list for further reuse.

Allocating each cache block separately and using a dedicated memory pool alone does not prevent memory fragmentation and induces a swath of metadata (in the heap) we’d have to manage for all the blocks. Instead, we can allocate our own memory pool (which is nothing but a contiguous block of memory). Still, since this also needs to be contiguous, it is rather unlikely that we’ll be able to allocate it all at once. As a result, we split this pool into smaller, equally sized segments, named Cache Buffers.
When initializing the Cache, we pre-allocate all the Cache Buffers we need, which ensures that we have enough memory reserved for our needs. Each Cache Buffer holds a fixed number of Cache Blocks. For example, 2MB Cache Buffers can hold 512 4KB Cache Blocks each.
Regarding empty cache blocks, keeping a single list of such blocks across all buffers would be hard to maintain (especially for a big cache), and we would quickly run into concurrency issues while modifying it. We have thus chosen to only keep such a list of empty cache blocks within each cache buffer (smaller concurrency domain). Across buffers, we employed a different approach. All buffers are initially added to a queue. When we need to use a new cache block, we pick the first buffer from this queue and use a block from it. If this results in the buffer filling up, we remove it from the queue. Consequently, if upon releasing a block (due to a deletion), a full cache buffer ends up having available capacity again, we add that buffer to the end of the queue.
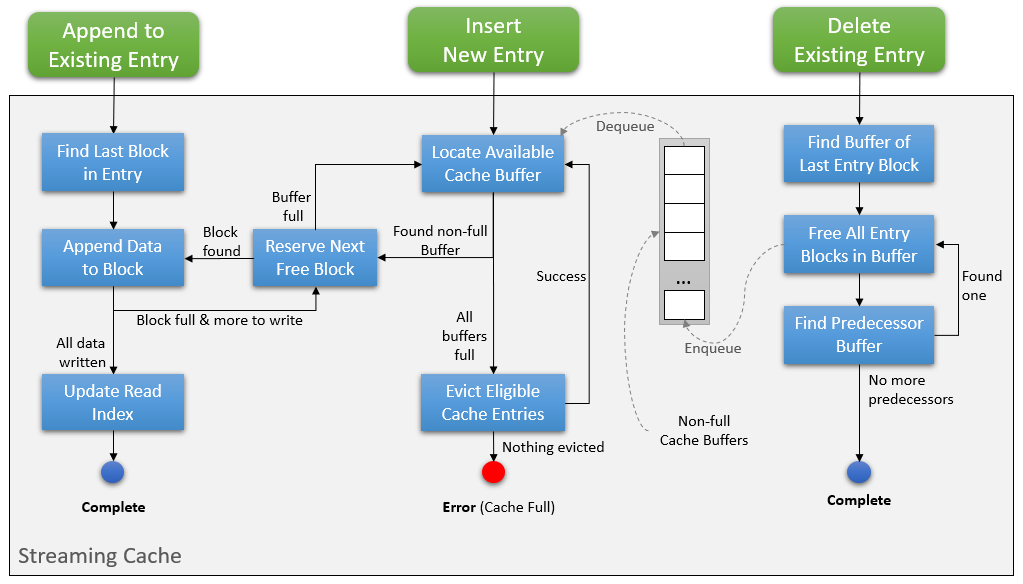
This approach solves the problem of wasted memory space due to allocator fragmentation, but it trades it for a different problem: Cache Entry fragmentation. For example, after a series of cache inserts and deletes involving entries of various sizes, the empty cache-block chain may not necessarily point to consecutive blocks. This is illustrated in Figure 2 above: if we were to insert Entry E3 (not depicted) which required 5 blocks, it would be stored in blocks 1, 4, 6, 7 and 14. Since these are not situated in contiguous memory, such a situation has the potential for performance degradation, especially or memory-swapped systems. However, we expect Pravega to be provisioned with sufficient memory for the entire Cache to fit in it and avoid swaps. This setup typically performs well under random access. In the future, we could alleviate this problem by improving our algorithm for Cache Entry allocation.
Putting everything together, the Streaming Cache is made up of a list of equally sized Cache Buffers, where each Cache Buffer is made up of equally-sized Cache Blocks. The first block of each Cache Buffer is reserved and contains metadata about each other block in that buffer. Such metadata includes whether a block is used, how much data it stores, what the previous block in its chain is (if used), and what the next free block is (if not used). The actual storage overhead is rather low. The only information stored in the Java heap is Cache Buffer pointers (which are essentially ByteBuffers), and the rest of the metadata is stored off-heap. When constrained with a maximum size, the Streaming Cache ensures that both the metadata and actual cache blocks count towards that, so it will never exceed its limits. The overhead is also easy to calculate: using 4KB Cache Blocks and 2MB Cache Buffers lets us use 511 of the 512 blocks per buffer, resulting in a constant 0.2% overhead (i.e., 8MB of overhead for a 4GB cache).
Let’s see the Streaming Cache in action using a concrete example, depicted in Figure 4 below.
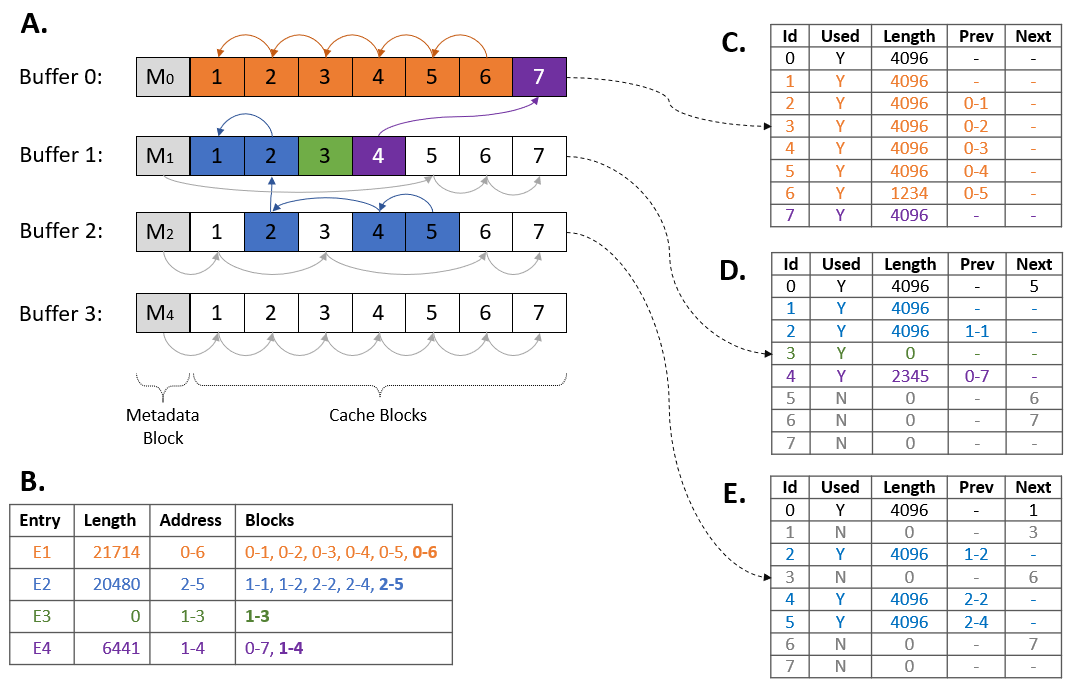
Figure 4 above depicts a cache with four entries. Section A shows a visualization of the layout, while Section B shows the same in tabular format. Entry E1 fits in 6 blocks, and all are located in Buffer 0. Since the last block is 0-6 (Buffer 0, Block 6), that will also serve as the address for the entry. Entry E2 fully occupies five blocks across Buffer 1 and Buffer 2. Although empty, E3 is a valid cache entry and does require a full cache block, even though it doesn’t store any data.
The metadata for Buffers 0, 1, and 2 are shown in Sections C, D, and E, respectively. The Prev column can be used to reconstruct the entry chain for a specific entry. For example, entry E4 with address 1-4 has a Prev value set to 0-7, which has no further Prev value; as such, E4’s chain is 0-7, 1-4. The Next column can be used to locate a free block. Buffer 0 (Section C) has no free blocks, but we can easily see that Buffer 1 has block 5 as its first free block (metadata block 0 has 5 in the Next column). Similar deductions can be made for the other entries and cache buffers. For an empty buffer, such as Buffer 3, each of its blocks points to the one right after it to form the unused block-chain.
Benchmarking
No change of this magnitude would have made it into Pravega unless it provided clear performance gains. We have executed several types of tests, starting with the Cache itself and then with it integrated into the Segment Store.
A quick note before we continue. As with any performance benchmark, results will vary based on the hardware and OS used, as well as the version of Pravega. All these were executed on a Dell® Optiplex™ 7040 with 8 Intel® Core™ i7-6700 CPUs @3.4Ghz and 64GB RAM running Ubuntu 16.04 with the code released as part of Pravega 0.7. The Segment Store test was executed using a single Segment Store instance using in-memory Tier 1 and Tier 2 (goal was to observe the cache effect). Each test was executed several times, and the best times were chosen (to get as close as possible to the real CPU time). The benchmark may output different values depending on the hardware and OS used.
Raw Cache Benchmarking
The goal of this test was to observe the amount of time that the Streaming Cache takes to do various operations that are typical of caches. The benchmark executes these types of tests:
- A sequential test, where one 1 million 10KB entries are inserted, then queried, then deleted from the Cache.
- A random test, where 1 million total operations were performed, and each operation had a 60% probability of being an insert and 40% of being a removal. Each time a random entry was picked for reading. This was done with both 10KB and 100KB entries.
We tested Java’s HashMap, the previous RocksDB-based cache implementation, and the Streaming Cache. The results are summarized in the following table and show the total times per operation/test, measured in milliseconds:
| Cache | Sequential Test | Random Test | |||
| Insert | Get | Delete | 10KB | 100KB | |
| HashMap | 2,516 | 2201 | 35 | 3,633 | 22,008 |
| RocksDB | 25,234 | 12,283 | 577 | 21,399 | 314,369 |
| Streaming Cache | 890 | 830 | 84 | 3,188 | 9,440 |
The Streaming Cache has done considerably better than the RocksDB-based Cache for all tests, and it even performed better than a HashMap-based cache. Let’s look at each case separately:
- HashMap has O(1) time complexity for both puts and gets, but since it’s a generic collection, it doesn’t hold the data – it keeps pointers to the data. As such, we must allocate/deallocate/copy the buffers that we store in it, otherwise we risk keeping references to deallocated buffers. For example, if the data originates from a socket buffer, that buffer may be released and we end up pointing to an invalid memory address.
- On the other hand, if we provide pointers to the internal byte arrays, that would allow external code to modify them without our knowledge. Copying the data into and out of the HashMap causes it to underperform compared to the Streaming Cache. We ran this test in two modes: one where we performed the copy (shown above) and one where we didn’t. The latter finished in about one-tenth of the time of the former – with all the extra time attributable to allocating new byte arrays and copying data from our buffers to that array or vice versa.
- RocksDB needs to maintain several indices and other data structures to provide the functionality that it does. Besides, it will also begin spilling to disk after specific triggers are met, which will cause the IO to slow down to whatever the backing disk speed is (this is most evident in the 100KB Random Test).
The HashMap cache does not deal with disk IO or complex data structures, but it is at the mercy of Java’s GC. Every call to Insert or Get will require a new byte array to be allocated, which could be stalled if the GC needs to make room for it. Furthermore, many such allocations and deallocations will cause fragmentation that the GC will need to resolve by compacting memory, which results in GC pauses that end up slowing the entire program.
The Streaming Cache performed better in all these tests due to it being tailored to the specific needs of the Segment Store. Insert operations do not need to allocate memory (Cache Buffers are pre-allocated), and the data are copied directly from the Netty buffers into the Cache. Get operations return read-only views of the cache entries, which allow copying their contents directly where they are needed (to the Tier 2 write buffers or Netty buffers – for Client reads). For fairness, we have simulated such copies after reading and included the extra time it took when benchmarking the Streaming Cache. The only test where HashMap fared better than Streaming Cache was deletion. That is because the Streaming Cache needs to free each used cache block, while the HashMap simply dereferences the byte arrays, deferring the actual memory reclamation to a later time (by the GC).
Segment Store Benchmark
Next, we integrated the Streaming Cache into the Segment Store and ran some ingestion performance tests. Virtually any change to Pravega can be benchmarked locally before the code even leaves the developer’s workstation. The Self Tester tool enables us to run various targeted tests that, if used properly, can show whether a proposed change is likely to improve performance or not.
We have executed a few tests, each focusing on different aspects of the Segment Store. Each test had 100 parallel producers sending Events/Updates in batches of 100 at a time. Throughput is measured in MB/s, while latency is measured in milliseconds. In the tests below, Baseline means Pravega 0.7 without Streaming Cache (using previous, RocksDB-based Cache). In contrast, Streaming Cache means Pravega 0.7 with Streaming Cache (the only different thing is the cache implementation).
Streaming Latency
This test aims to measure latency with small appends (100 bytes).
| Type | TPut | LAvg | L50% | L90% | L99% | L99.9% |
| Baseline | 87 | 56 | 13 | 107 | 558 | 878 |
| Streaming Cache | 91 | 46 | 17 | 109 | 161 | 362 |
Self Test args: -Dtarget=InProcessStore -Dbkc=0 -Dcc=0 -Dssc=1 -Dc=1 -Ds=1 -Dsc=4 -Dp=100 -Dpp=100 -Dws=1000 -Do=2000000.
Streaming Throughput
This test aims to measure throughput with medium-sized appends (10KB).
| Type | TPut | LAvg | L50% | L90% | L99% | L99.9% |
| Baseline | 137 | 541 | 276 | 1,414 | 3,261 | 3,604 |
| Streaming Cache | 431 | 130 | 95 | 246 | 797 | 1,077 |
Self Test args: -Dtarget=InProcessStore -Dbkc=0 -Dcc=0 -Dssc=1 -Dc=1 -Ds=1 -Dsc=4 -Dp=100 -Dpp=100 -Dws=10000 -Do=1000000.
Wrap up
Caching plays a central role in the ingress and egress performance of Pravega. Tail reads are served exclusively from the Cache, and historical reads use it to store prefetched data – they are staged in the Cache after being read from Tier 2 until consumed by a reader. Nearly every user operation in Pravega touches the Cache in one way or another. The choice of Cache can make or break Pravega’s throughput and latency, and it can be the difference between a cluster that responds in near-realtime and one that crumbles under heavy load. By eliminating the overheads that typical cache implementations have, the Streaming Cache offers a fast, efficient way to temporarily store large amounts of streaming data using a block-based, index-less layout. Adopting it has solved several bottlenecks that we identified on the ingestion path, enabling us to reduce the tail latencies for throughput-heavy workloads significantly.
Acknowledgments
Thanks to Srikanth Satya and Flavio Junqueira for the comments that helped to shape this post.
About the Author

Andrei Paduroiu is among the original group of developers who started the Pravega project and is currently a core contributor, owning the data plane server-side aspects of it – the Segment Store. He holds a MS Degree from Northeastern University and a BS Degree from Worcester Polytechnic Institute. Currently working for DellEMC, Andrei previously held software engineering positions with Microsoft and Vistaprint. Andrei’s interests include distributed systems, search engines, and machine learning.