
The ability to pipeline Events to the Segment Store is a key technique that the Pravega Client uses to achieve high throughput, even when dealing with small writes. A Writer appends an Event to its corresponding Segment as soon as it is received, without waiting for previous ones to be acknowledged. To guarantee ordering and exactly once semantics, the Segment Store requires all such appends to be conditional on some known state, which is unique per Writer. This state is stored in each Segment’s Attributes and can be atomically queried and updated with every Segment operation.
Over time, Attributes have evolved to support a variety of use cases, from keeping track of the number of Events in a Segment (enabling auto-scaling) to storing a hash table index. The introduction of Table Segments (key-value stores which contain all of Pravega’s Stream, Transaction and Segment metadata) required the ability to seamlessly manage tens of millions of such Attributes per Segment.
This blog post explains how Segment Attributes work under the hood to provide an efficient key-value store that represents the foundation for several higher-level features. It begins with an overview of how Pravega Writers use them to prevent data duplication or loss and follows up by describing how Segment Attributes are organized as B+Trees in Tier 2 using innovative compaction techniques that reduce write amplification.
Preventing Duplication or Loss using Attributes
The EventStreamWriter must always know the “state” of its already written data on the server before writing more, even in the face of common failure scenarios. This involves it supplying some value that the server can check and update atomically with every modification that is attempted. Most problems manifest themselves by the Event never being ack-ed back, in which case the originating EventStreamWriter retries sending it with the same condition as before. If the Event has already been persisted in the previous attempt, the Segment Store rejects the retry with a ConditionalAppendFailedException and the EventStreamWriter will ack that Event to its caller and move on to its next Event(s). Conversely, if the Event hasn’t been persisted in the first place, the Segment Store will do so now and ack it to the Writer. The combination of retry and conditional failure help prevent data loss (Event was never persisted) and duplication (Event was persisted, but the ack was never processed).
Each EventStreamWriter has a unique Writer Id and can write to multiple Segments at once, depending on the Routing Key used for the Events it is processing. Its internal state is made up of a map of Event Numbers for each Segment it interacts with, that is updated every time it needs to process a new Event. Every Event is sent to the Segment Store as a conditional append (conditioned on the Event Number for its Writer Id on that Segment to match what it should be). The Segment Store’s Ingestion Pipeline processes all appends in the order in which they were received, and each conditional append is atomically checked, committed and updated, thus ensuring the consistency of the stored data.
The Segment Store maintains this state in the form of Segment Attributes. An example of how this works is evidenced in Figure 1.
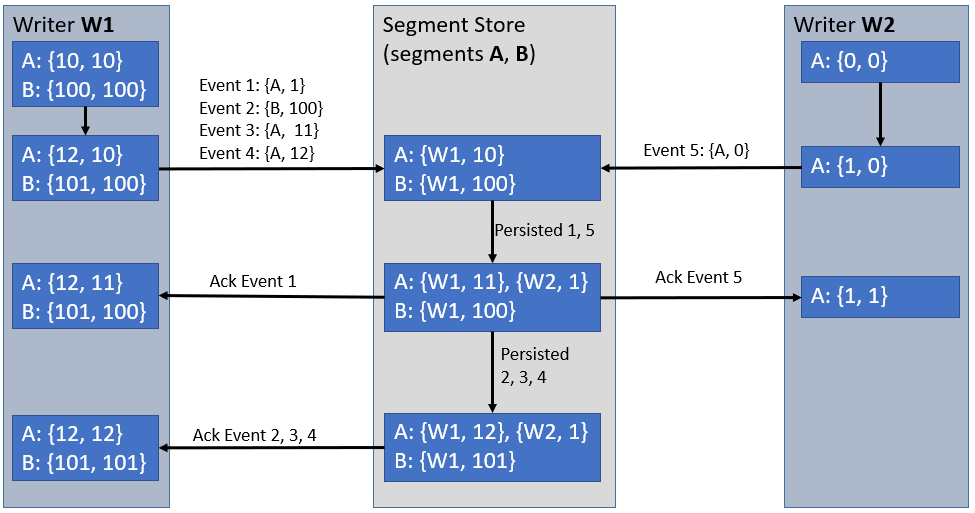
Segment Attributes
Each Stream Segment has an associated set of attributes that can be used either independently or in combination with various segment operations. For example, we can choose to only update some attributes, or we can choose to atomically append to a segment and update some of its attributes.
Writer Ids are 128-bit UUIDs and Event Numbers are 64-bit Longs, as such we have chosen Segment Attributes to be key-value pairs with 16-byte keys and 8-byte values. There are two types of Attributes: Core Attributes, which have hardcoded ids and are used to keep track of the internal state of the Segment (such as total event counts, scaling policy, etc.) and Extended Attributes which are externally specified and don’t have any meaning internally. Both types have the same semantics, with the only difference being that core attributes are pinned to memory while extended attributes can be evicted. Writer Ids are mapped to Event Numbers using Extended Attributes.
Attributes can be updated using one of the following verbs:
- Replace: the value of an Attribute is set or updated to a new value.
- Replace-If-Greater: the value of an Attribute is updated to a new value v, if there exists a current value v’ and v > v’.
- Replace-If-Equals: the value of an Attribute is updated to a new value v, but only if the current value matches v’ (supplied by the caller). This is the classical compare-and-set, which can also be used to ensure an attribute is not currently set before updating it.
- Accumulate: the value of an Attribute is updated to its current value plus a value supplied by the caller.
Here is an example adapted from Pravega’s Segment Store code that illustrates how Segment Attributes can be used:
In this code, we touch two attributes for each append: conditionally update the Writer’s Event Number to a new value, and then we update the number of Events stored in the Segment. The Segment Store’s Ingestion Pipeline atomically performs the following on the segment this append touches (append.getSegment()):
- Verify the value of
append.getWriterId()matchesappend.getLastEventNumber(). - Update
append.getWriterId()toappend.getEventNumber(). - Update
Attributes.EVENT_COUNTto its previous value +append.getEventCount(). - Append
append.getData()as a contiguous sequence of bytes at the end of the Segment.
Storing Attributes
Attributes serve as extra metadata associated with each Segment. They can be set or retrieved by the Client at will. However, they are not exposed externally by any API. Should this be their only use, it would have sufficed to store Attributes in a separate, internal Segment associated with the main one. But, as evidenced above, Attributes are also heavily used in various computations inside the Ingestion Pipeline, and we would be introducing a severe performance penalty if we halted the pipeline every time we had to fetch the value of an Attribute from its storage. We need a way to cache either all or a subset of Attributes in a memory data structure that can be easily accessed and modified by the Ingestion Pipeline, but also a way to eventually persist those updated values in Tier 2 Storage in an efficient manner.
To solve this, we settled on a two-level caching solution that sits atop the Tier 2 Attribute Segment that ultimately stores all Attribute values. The first cache is a plain Java HashMap that keeps the most recently used Attributes – this directly maps keys to values, making lookups and updates very efficient. The lower-level cache keeps portions of the Tier 2 Attribute Segment in memory in raw format – this requires deserialization to extract information, but accessing it is significantly faster than reading it from Tier 2. The lower-level cache and Tier 2 Attribute Segment together make up the Attribute Index, which organizes the Segment Attributes in a data structure adapted for storing on append-only media.
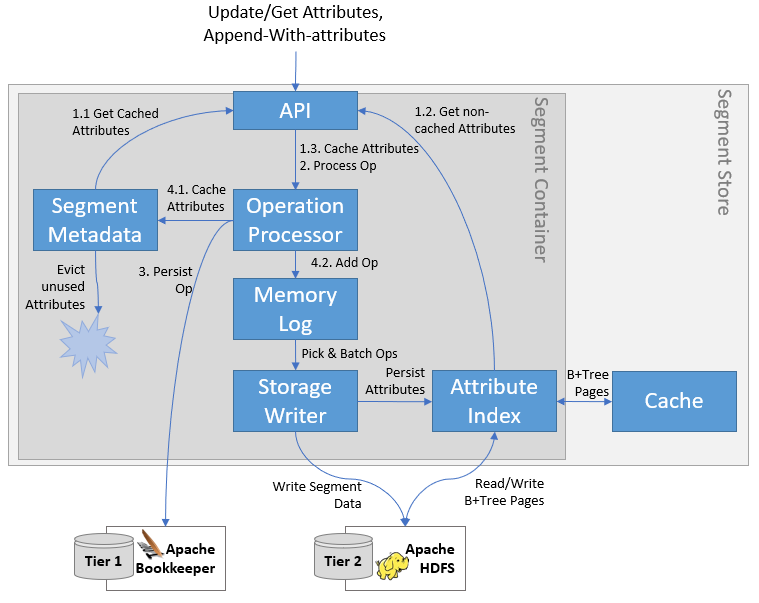
One of the key decisions we’ve made to avoid having to fetch Attribute values from Tier 2 inside the Ingestion Pipeline was to prefetch them before processing the operation. Steps 1.1 through 1.3 in the diagram above show how this works. We query the metadata for any Attributes that already have a value in memory (1.1) and fetch the remaining from the Attribute Index (1.2). To ensure consistency across concurrent requests for the same data, we load the Attributes in the Segment Metadata via the Ingestion Pipeline using conditional attribute updates (1.3) – if they are already loaded, then we don’t want to overwrite that value with a potentially stale one.
To persist the Attribute values in Tier 2, we make use of infrastructure that is already in place. The Storage Writer aggregates smaller Segment Appends into larger buffers to write them to Tier 2, but it can also combine attribute updates into larger batches for persisting into Tier 2 via the Attribute Index. This has the added benefit that frequently-updated attributes (such as Event Numbers) do not need to persist every change to Tier 2 – we can coalesce multiple such updates together (keeping only the latest value), so we avoid having to do unnecessary, costly Tier 2 writes.
Attribute Index
Probably the biggest challenge that we had to overcome was how to store a large number of Attributes in Pravega’s Tier 2. First things first: how big of a number are we talking about? Realistically there may only be as many as a few thousands of Writers to a single Segment, so do we need to design for more?
Our initial approach optimized for less than 100K Attributes per segment and was straightforward: we appended every update (24 bytes) to the Attribute Segment, and after writing a few MBs of data we compacted everything into a sorted array and appended that as well. We kept a pointer to the beginning of the last compaction and when we had to read, we read the whole section of that segment until the end. This was simple, had few moving parts, and handled our use case well (100K attributes meant about 2.5-5MB of data in Tier 2 – easy to read at once and to cache).
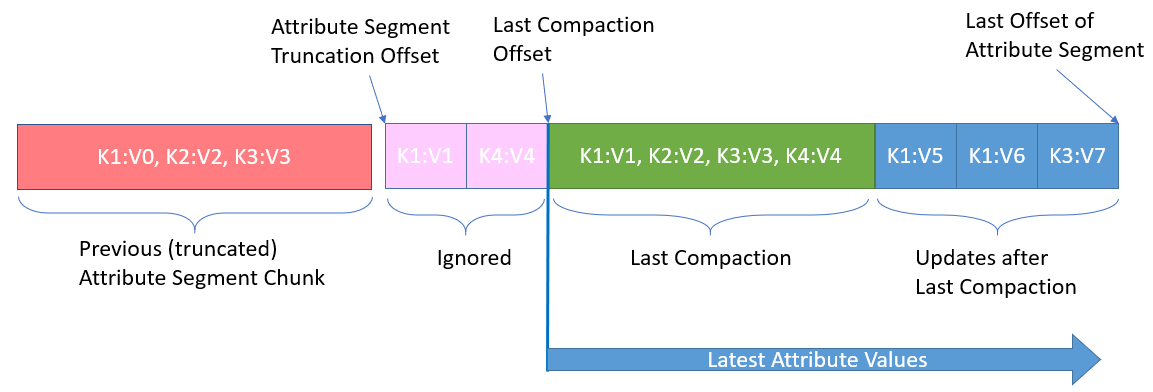
Looking into the future, we found another great use for Attributes. Table Segments, introduced in Pravega 0.5 to store all of Pravega’s metadata, expose a Key-Value API backed by regular Pravega Segments. Being a hash table, they store their entire index in the Segment’s Attributes and thus require substantially more Attributes per Segment than EventStreamWriters. We realized that we would need to support something in the order of tens of millions of Attributes for each Segment, which would require a completely different approach to storing them in Tier 2. The solution came in the form of B+Trees, however the implementation that we chose is slightly different than what one would find in a typical database system.
B+Trees on Append-Only Storage
When the only allowed modification is appending at the end of a file, B+Trees are not usually the first choice as an index structure. Append-only B+Trees have been implemented before but they all have a significant drawback: write amplification. Every modification to such a structure requires re-appending all the nodes on the path from the root to the updated data node back into the file. Over time, this leads to excessive file sizes which contain a lot of obsolete data. Periodic full compaction of the index solves this, but such an approach would not work for Pravega. Due to the distributed nature of our system, node failure is expected, so any lengthy, non-atomic operation such as compaction would be challenging to get done correctly and without affecting the runtime performance of the Segment Store. Another approach would have been to use an LSM Tree, but such a data structure also makes use of heavy compaction. As a result, we have employed a few techniques and optimizations that allow us to efficiently store Segment Attributes in a B+Tree stored in Tier 2.
Knowing that our keys and values are always the same lengths (16 bytes and 8 bytes, respectively) enabled us to simplify the B+Tree node structure and allow for a large branching factor. Setting the maximum node size to 32KB and using 32 bytes per entry (key, value, extra metadata) gives us a branching factor of just over 1000. For an index holding up to 1,000,000,000 entries, we need to make at most 3-4 reads from Tier 2 to lookup a key.
Even though the key we are looking for may be a few levels deep, virtually any B+Tree operation needs to query the root, and each second-level node has a 1 in a 1000 chance to be queried. Caching nodes dramatically reduces the need to read at arbitrary offsets from Tier 2, especially for the higher-level nodes. With a maximum node size of 32KB, the entire second level needs up to 32MB of cache space so we can easily keep all those nodes in memory. The cache hit rate can vary significantly depending on the access patterns involved, but our testing has shown that, on a warm index, locating a key may require no more than one Tier 2 read when caching is used.
The high branching factor may alleviate write amplification, but it doesn’t eliminate it. However, a key observation is that even though the Attribute Segment would grow indefinitely, the live data (most recent version of the nodes) is concentrated towards the end of the Segment, while the beginning tends to have mostly obsolete data. By applying the same technique used for enabling Stream Retention, we can perform head truncation by deleting the Segment Chunks that have been truncated out. A Segment Chunk is a contiguous sequence of bytes that represents a section of a Segment; Segments are split into equal-sized chunks, with each chunk being a single file/object in Tier 2. As such, using the already-built Rolling Storage adapter for Attribute Segments got us closer to our desired goal.
However, we can only perform head truncation if we are confident that the discarded data does not contain any B+Tree nodes that are still in use. The beginning of the Segment contains mostly obsolete data (nodes that have since been updated and thus re-appended), but it may contain the occasional B+Tree node that is still active. A classic compaction would take care of this: scan the index file, find the earliest nodes that are surrounded by obsolete data, and move them to the end of the file by performing an append. While that would unblock truncation, it would still require a lengthy, non-atomic compaction process that had to be managed for a large number of segments at the same time.
We have chosen instead to do progressive compaction. Every time we modify the B+Tree, we identify the node with the lowest offset in the Attribute Segment and move it to the end by re-appending it (which may involve moving its ancestors as well). While this may look like we are making our write amplification problem worse, it is an acceptable trade-off for keeping the Attribute Segment file small. Tier 2 writes are considered high-throughput, so it makes little difference if we tag an additional 32-100KB to each. What we get in return is the ability to truncate a larger chunk of data from the beginning so we can actually keep the size of the Attribute Segment within reasonable bounds.
To locate the node with the smallest offset, each B+Tree index node contains the lowest segment offset of any B+Tree node in the sub-tree that begins from it. Knowing this value allows us to quickly locate the node with lowest offset by following its path from the root node. Maintaining it is also straightforward: since every update requires modifying all nodes from the leaf to the root, all we need to do is recalculate this value for each node using the existing data already encoded in it and the new offsets for the modified pages; we do not have to do any extra IO, so there is no impact on performance.
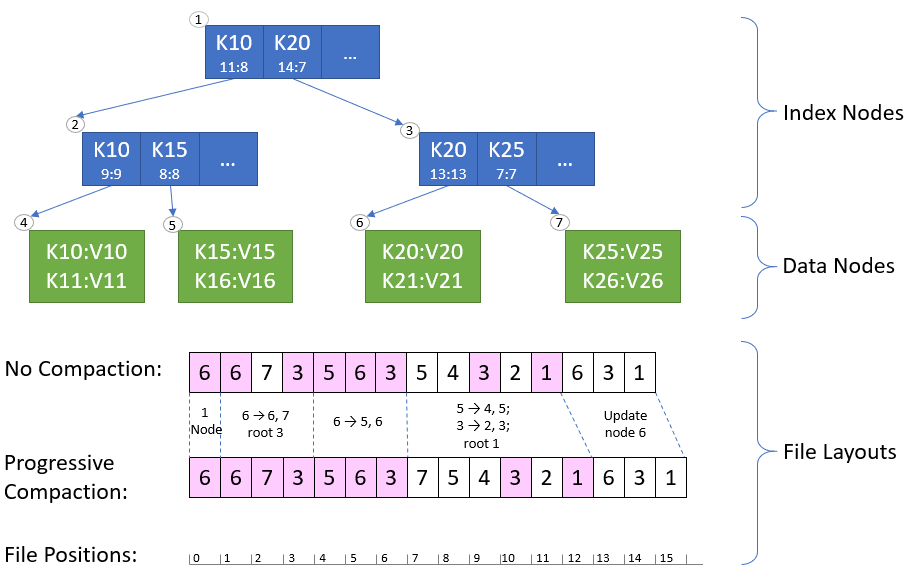
Let’s have a look at how the file layout evolves as a result of the steps that created the B+Tree in Figure 4:
- We begin with a single-node tree made of Node 6.
- In both cases, we append node 6.
- Node 6 splits into 6, 7 and Node 3 is created as root and has 6 and 7 as children.
- In both cases, we append nodes 6, 7, 3. File layout is 6, 6, 7, 3.
- For Progressive Compaction, we skip re-appending 6 since it’s already included in the update.
- Node 6 splits into 5, 6. Node 3 has 5, 6 and 7 as children.
- In both cases we append nodes 5, 6, 3. File layout is 6, 6, 7, 3, 5, 6, 3.
- For Progressive Compaction, we skip re-appending 6 since it’s already included in the update.
- Node 5 splits into 4, 5; Node 3 splits into 2, 3 and Node 1 is created as root. Node 1 has 2 and 3 as children, Node 2 has 4 and 5 as children and Node 3 has 6 and 7 as children.
- No Compaction: we append nodes 5, 4, 3, 2, 1. File layout is 6, 6, 7, 3, 5, 6, 3, 5, 4, 3, 2, 1.
- Progressive Compaction: we append 7 (lowest-offset node), then 5, 4, 3, 2, 1. File layout is 6, 6, 7, 3, 5, 6, 3, 7, 5, 4, 3, 2, 1
- Node 6 is updated. No structural changes to the tree.
- In both cases we append nodes 6, 3, 1.
- For Progressive Compaction, we skip re-appending 6 since it’s already included in the update.
- No compaction layout: 6, 6, 7, 3, 5, 6, 3, 5, 4, 3, 2, 1, 6, 3, 1.
- Progressive compaction layout: 6, 6, 7, 3, 5, 6, 3, 7, 5, 4, 3, 2, 1, 6, 3, 1.
In this example, using Progressive Compaction allows us to truncate the Attribute Segment at position 7 (vs position 2 in the no-compaction case), thus helping us free disk space that is no longer needed.
Progressive Compaction in Practice
To verify how Progressive Compaction works in the “real world”, we designed and ran a few experiments. By combining multiple updates into a single batch, we can reduce the write amplification since, the bigger the batch, the fewer times the B+Tree has to rewrite its top-level nodes. We used different insert/update batch sizes and compared the size of the index (in Tier 2) with and without compaction. The batch sizes used in these tests are representative of how the Storage Writer aggregates updates: smaller batches for Segments with a few concurrent Writers, while larger ones are typically found in Table Segments.
| Batch Size | Index Size | |
| No Compaction |
Progressive Compaction |
|
| 10 | 3,991 MB | 115 MB (3%) |
| 100 | 416 MB | 97 MB (23%) |
| 1,000 | 60 MB | 54 MB (89%) |
Table 1: Inserting 1,000,000 Segment Attributes in sorted order. For smaller batch sizes, progressive compaction had the biggest effect (97% reduction), while larger batches did not (due to less write amplification).
| Batch Size | Index Size | |
| No Compaction |
Progressive Compaction |
|
| 10 | 32,990 MB | 72 MB (0.22%) |
| 100 | 29,402 MB | 103 MB (0.35%) |
| 1,000 | 17,083 MB | 91 MB (0.53%) |
Table 2: Bulk-loading 1,000,000 Segment Attributes, then updating all of them in a random order. Regardless of the batch size, the write amplification was so severe that Progressive Compaction had a significant effect – reduced the index size by at least 99.5%.
Wrap-Up
Attributes play a central role in the life of a Pravega Stream Segment. Aside from storing metadata about a Segment, they actively participate in the operations that modify it. They are used to keep statistics about a Segment (how many events are stored in it) and enable exactly-once semantics for EventStreamWriters. Using an innovative approach to a traditional data structure enables the Segment Store to manage up to a billion attributes per segment without any significant effort. Progressive compaction reduces the effect of write amplification on append-only B+Trees by up to 99.5% without the use of background tasks or affecting performance.
In one of our next posts, we will explore how we can use Segment Attributes to implement a durable hash table backed solely by Pravega Segments – the first step in creating a massively distributed metadata store in Pravega.
Acknowledgments
Thanks to Srikanth Satya and Flavio Junqueira for the comments that helped to shape this post.
About the Author

Andrei Paduroiu is among the original group of developers who started the Pravega project and is currently a core contributor, owning the data plane server-side aspects of it – the Segment Store. He holds a MS Degree from Northeastern University and a BS Degree from Worcester Polytechnic Institute. Currently working for DellEMC, Andrei previously held software engineering positions with Microsoft and Vistaprint. Andrei’s interests include distributed systems, search engines, and machine learning.