
This blog post provides an overview of how Apache Flink and Pravega Connector works under the hood to provide end-to-end exactly-once semantics for streaming data pipelines.
Overview
Pravega [4] is a storage system that exposes Stream as storage primitive for continuous and unbounded data. A Pravega stream is a durable, elastic, append-only, unbounded sequence of bytes providing strong consistency model guaranteeing data durability (once the writes are acknowledged to the client), message ordering (events within the same Routing Key will be delivered to the readers in the same order as it was written) and exactly-once support (duplicate event writes are not allowed).
Pravega was designed to support a new generation of streaming applications which process large amounts of data arriving continuously to derive deep insights. Pravega relies on the stream processing frameworks to process and transform the data, and it provides enough storage primitives that are necessary for a stream processing framework to operate on the data and reason about it.
Apache Flink is a distributed stream processor with intuitive and expressive APIs to implement stateful stream processing applications. By combining the features of Apache Flink and Pravega, it is possible to build a pipeline comprising of multiple Flink applications, that can be chained together to give end-to-end exactly-once guarantees across the chain of applications.
The Pravega Flink Connector is a data integration component that enables Apache Flink applications to perform read and write operations over Pravega streams.
A stream data that an application needs to process could be either bounded (start and end positions are well-known) or unbounded (continuous flow of data where the end position is unknown). A stream processor may have to process the stream data in multiple interconnected stages to perform a series of data transformations to arrive at the results. This notion of stream data undergoing various transformations as part of the data processing mechanism could be termed as “Data Pipeline.” A data pipeline can be visualized as a directed acyclic graph (DAG), where each edge represents the data flow, and each vertex (transformation) represents an operational logic applied to the data.
A typical data pipeline will have a source and a sink operator:
Source Operator: Acts as the front-end of the data pipeline and is responsible for consuming the streaming data from an external data source.
Sink Operator: The Sink is the final operator in the data pipeline and is responsible for persisting the computed results of the streaming application to an external data source.
All other operators that are connected between the source and sink operators perform data processing operations like filtering, transforming, etc., and might maintain some application state.
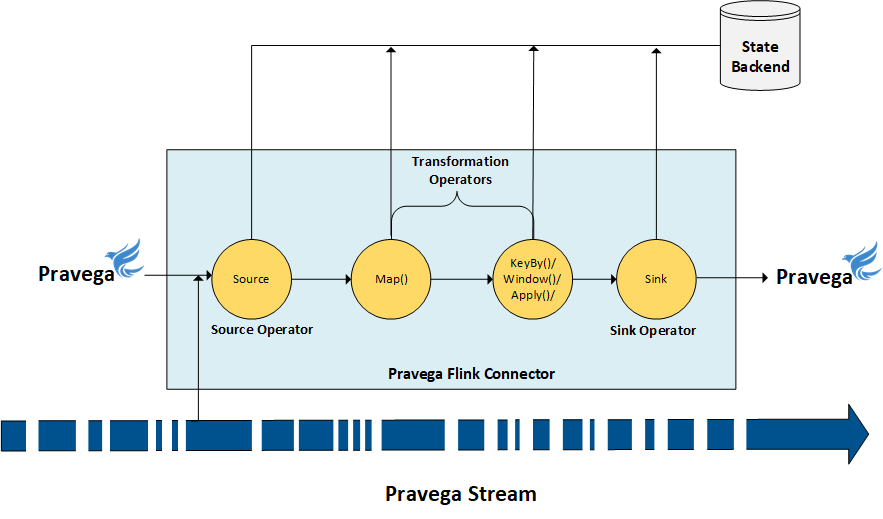
The above flow is a simplified view of a data pipeline, but for production use, the data pipeline could be complex having multiple parallel operators, and each operator (including the source and sink) could run with varying parallelism (instances) to support data analytics operations at scale.
Flink provides API semantics to perform stateful computations over bounded and unbounded data streams. Bounded data streams have a defined start and end boundaries. The computations performed over the bounded data streams is known as batch processing. In the event of a failure, any application state that was maintained will be lost and restarting the job will reprocess the events from the starting boundary offset. On the contrary, an Unbounded data stream have a start, but no end boundary and the data must be continuously processed. In the event of a failure, though it is possible to reprocess the events from the starting boundary offset, it is highly undesirable as it must process a large volume of data, spending cycles in duplicating the processing efforts. Since the computation is stateful, the data processing framework needs to ensure backing up the operator state and the input/output offsets. It is essential to recover from any failure, and the framework needs to guarantee that each incoming event will be processed exactly once by all the operators, even in the event of an application failure.
Processing Guarantees
Stream processing applications are prone to failures due to the distributed nature of deployment that it needs to support. Since tasks are expected to fail, the processing framework needs to provide guarantees concerning maintaining the consistency of the internal state of the stream processor despite crashes. The application must observe a consistent state after recovering compared to the state before the crash.
There are broadly three categories for reliability semantics [1] that stream processing frameworks are expected to satisfy:
At-most-once (Only-once-Type-1 [1])
An implementation of at-most-once semantics does not attempt to retransmit or retry operations in the presence of connection drops or crashes. Not attempting to retransmit guarantees makes it possible that some events are not delivered and processed. It also guarantees that no event is delivered and processed multiple times. An application that favor progress over completeness typically make use of this option.
At-least-once
With at-least-once semantics, the framework makes as many attempts as needed to guarantee that any given event is delivered and processed at least once. A typical implementation consists of retrying until an acknowledgment is received. Because of the multiple attempts, it is possible that an event is delivered and processed multiple times. Applications that favor completeness over progress typically make use of this option.
Exactly-once (Only-once-Type-2 [1])
Exactly-once semantics introduces additional mechanisms to guarantee that all events are delivered and processed but never processed multiple times. Applications that favor completeness and are sensitive to duplicates require this option.
Delivering End-to-End Exactly-Once Guarantee
In the following sections, we will see how both Pravega and Apache Flink support end-to-end exactly-once semantics. We start by discussing the mechanisms that Flink provides, followed by what Pravega provides.
Apache Flink (Exactly-Once)
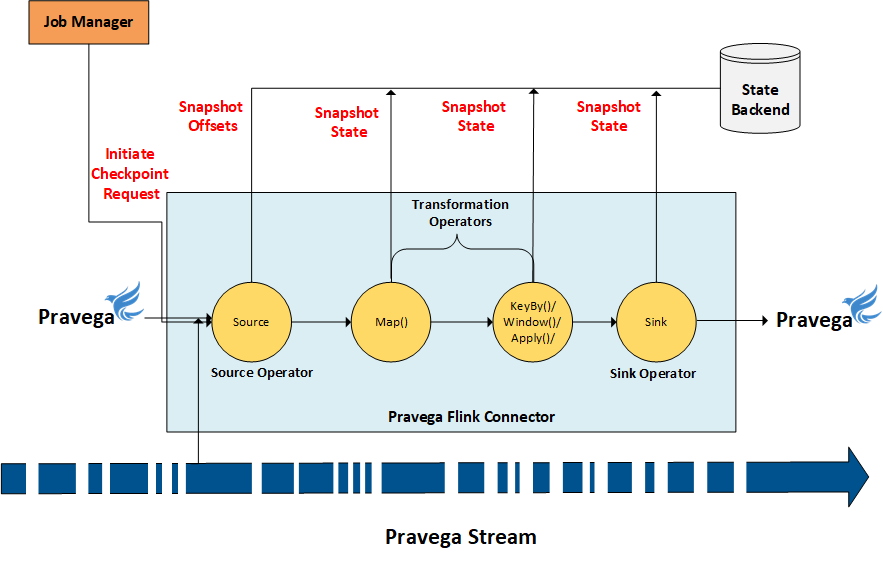
Flink supports exactly-once guarantee with the use of distributed snapshots [2]. Flink draws a consistent snapshot of all its operator states periodically (checkpoint configuration interval) and stores the state information in a reliable distributed state backend storage. By doing so, it allows the Flink application to recover from any failures by restoring the application state to the latest checkpoint.
The Flink snapshot algorithm is based on stream barriers that flow through the operators. The barriers are first injected at the Source operator, and it flows through the operator chain (downstream operators) till the Sink. Each operator, upon receiving the barrier will snapshot its state to the state backend storage, ensuring the possibility of state recovery upon any failures.
An operator first aligns its barrier from all incoming partitions and upon receiving barriers from every incoming stream, it performs a checkpoint of its state to the durable state backend storage. After the snapshot has been taken, the operator forwards the barrier to the downstream operators for it to draw its snapshots.
The Source operator records the current offset of the Reader that it is currently working on. Similarly, for the Sink operator, if the external data source supports transactional operations (Commit/Rollback), then Flink makes use of the two-phase commit protocol [3] to record and maintain the application state.
By maintaining a consistent snapshot of the application state, Flink ensures that upon any failures, the application can be restarted from the most recent snapshot. During the application restart phase, the Source, Sink and other operators are rewind to the state before the application failure, and thereby it ensures the end-to-end exactly-once guarantee.
Pravega (Exactly-Once)
Pravega supports exactly-once semantics by ensuring that the data is not duplicated during both read and write operations, and no events are missed despite failures. Pravega streams are durable, ordered, consistent, and transactional.
Duplication of events could occur during the following two scenarios.
1) A writer application which is writing events to Pravega fails to get the acknowledgment over the network. It is possible that the event might have been successfully written, but only the acknowledgment operation failed. Does this put the application in a spot since the writer was not aware if the data has been successfully written or not? In response to the failure, the application could attempt to rewrite the event as an act of recovery process, which might result in duplicate event if the server is not capable of handling this type of request. Pravega addresses this problem by supporting idempotent writes and transactions.
2) The other scenario could stem from the fact that the readers that are reading events from a stream could end up in processing duplicate events if the reader offsets are not appropriately managed. A failed reader when restarted should not reload the events that are already consumed and processed. Pravega addresses this problem by allowing the readers in the Reader Group to periodically checkpoint the reader state and ensure that duplicate events are not routed across the readers.
Routing Key: In Pravega, data is written with an application-defined Routing Key. A Routing Key is a string used by developers to group similar Events. A Routing Key is often derived from data naturally occurring in the Event, like “customer-id” or “machine-id” or a declared/user-defined string. For example, a Routing Key could be a date (to group Events together by time) or it could be an IoT sensor id (to group Events by machine). A Routing Key is vital in defining the read and write semantics that Pravega guarantees. Pravega guarantees order per Routing Key: two events with the same Routing Key will be placed in the same bucket in the order in which it is being written. The Reader application is ensured to see these events from the bucket in the same order as it was written.
Reader: All Readers see the same ordered view of data for a given Routing Key, even in the case of recovering after a failure. This property is essential for building accurate data processing in the event of any failures.
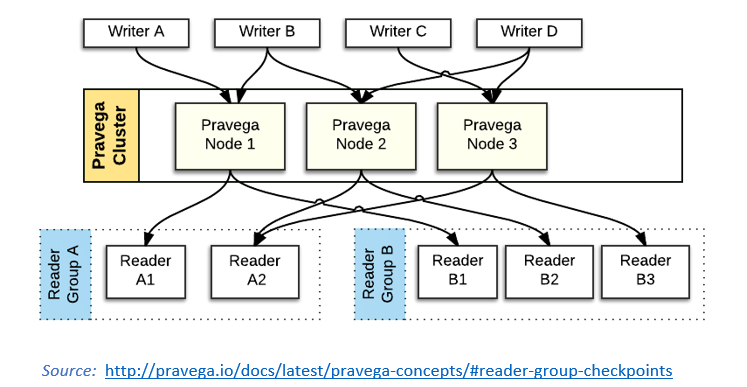
Reader Groups: Readers are grouped into Reader Groups to read from one or more Streams in parallel. For any Reader Group reading a Stream, each Stream Segment is assigned to one Reader in that Reader Group.
Writer: Writes are idempotent. If a Writer is attempting to perform a rewrite because of an intermittent connection failure, the writes will not be duplicated. However, any re-attempt by the writer after it crashes will not guarantee non-duplicate writes since there is no way to determine if the event has been previously written or not. For scenarios where we expect the writer to crash and recover, we need to rely on transactional write mode support (Pravega Transactions) to avoid duplicating the events.
Pravega supports transactional writes to ensure that the set of events are written atomically. The data is written to the stream only when it is committed. A transaction can be abandoned implicitly (when a Writer is crashed) or explicitly with the use of abort transaction API call. When an application opens a transaction using the Transactional Writer instance, a transaction identifier reference is provided, and it can be used by the application to resume a transaction in the event of an application crash.
Role of external Data Source in supporting End-to-End Exactly-Once guarantee
A stream processing application can provide end-to-end exactly-once guarantee only when the external data source (to which the source and sink operators are interacting) supports the following:
- An event will not be delivered more than once (duplicate events) to any source operator, i.e., if there are multiple source operators (say parallelism > 1) that are reading from the external data source, then each source operator is expected to see unique sets of events and the events are not duplicated across the source operators.
- Source operator should be able to consume data from the external data source from a specific offset.
- The sink operator should be able to request the external data source to perform a commit or rollback operations.
Flink Pravega Connector (Exactly-Once)
The Connector enables users to build end-to-end stream processing pipeline that can Read and Write Pravega Streams with the Apache Flink Stream processing framework. The connector offers seamless integration with Flink infrastructure, thereby ensuring parallel Reads/Writes, exposing Pravega Streams as Table API records, checkpointing and guaranteeing exactly-once processing with Pravega.
In this section, we will walk through the implementation details of how the connector enables exactly-once processing with Flink and Pravega integration.
Let’s imagine a simple Flink streaming application that uses Pravega as a source. The source data contains application log data, and we do a window operation (e.g., tumbling window every 5 minutes) (see above Figure) to identify error pattern and finally sinking the results to a Pravega stream. The Flink cluster is configured to use HDFS (We are working on providing Pravega based state backend support for Flink and this will eliminate the need for an external storage dependency like HDFS) as a state backend to persist the checkpoint state. The Flink job is configured to perform checkpoint every fixed number of interval (say every 1 minute).
Source (FlinkPravegaReader)
Let’s establish some basic understanding of how Pravega Reader implementation works before we jump into FlinkPravegaReader implementation.
Readers are organized into Reader Groups. A Reader Group [5] is a named collection of Readers, which together perform parallel reads from a given Stream. Pravega guarantees that each Event published to a Stream is sent to exactly one Reader within the Reader Group. There could be one or more Readers in the Reader Group, and there could be many different Reader Groups simultaneously reading from any given Stream. Each Reader in a Reader Group is assigned zero or more Stream Segments. The Reader assigned to a Stream Segment is the only Reader within the Reader Group that reads Events from that Stream Segment.
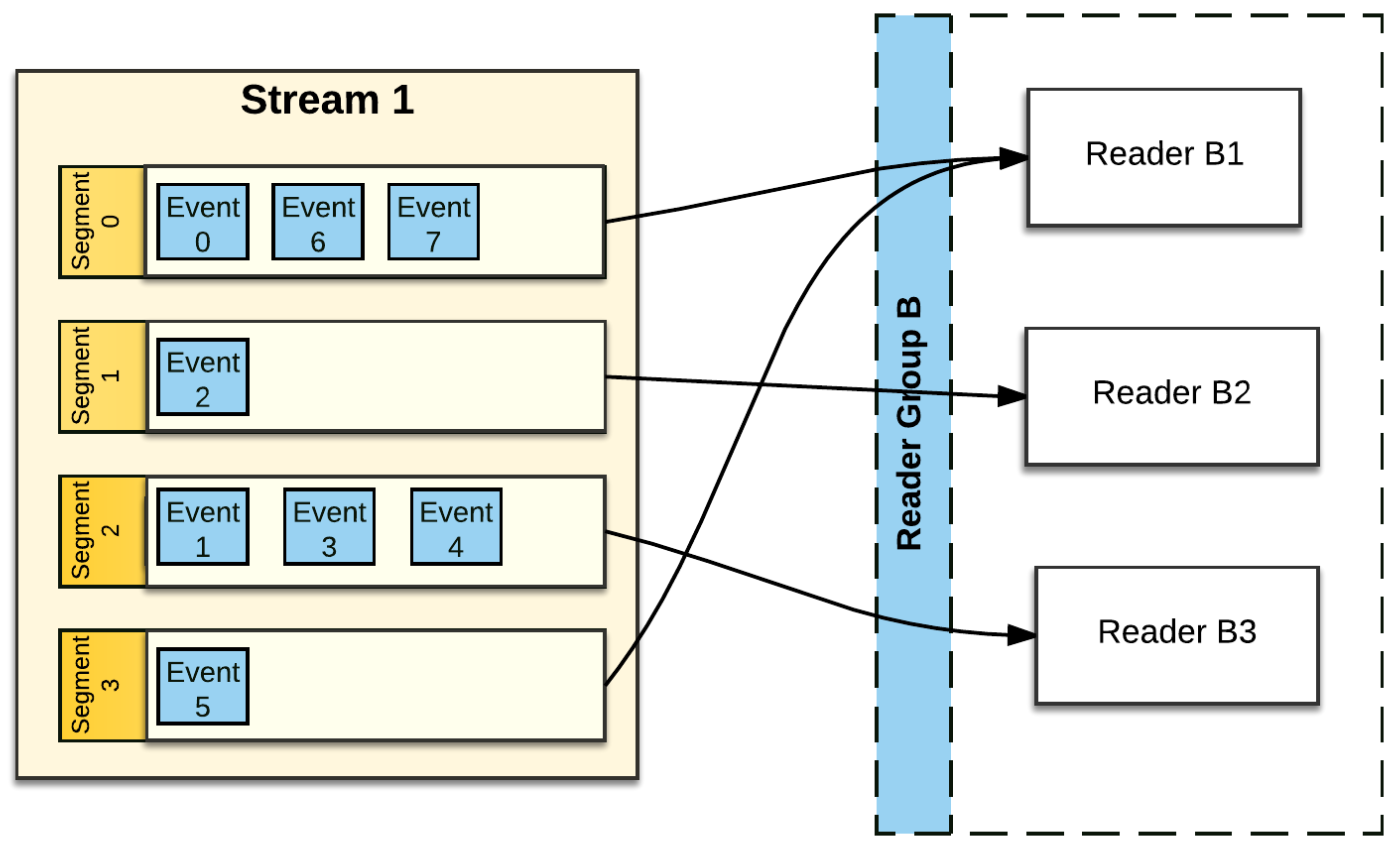
Pravega provides the ability for an application to initiate a Checkpoint on a Reader Group. The idea with a Checkpoint is to create a consistent “point in time” persistence of the state of each Reader in the Reader Group, by using a specialized Event (Checkpoint Event) to signal each Reader to preserve its state. Once a Checkpoint has been completed, the application can use the checkpointed state to reset all the Readers in the Reader Group to the known consistent state represented by the Checkpoint.
The Flink Pravega Reader implementation uses the Flink ExternallyInducedSource interface which allows the Source operator to let Pravega Reader Group perform a snapshot of the Reader position before finalizing its Checkpoint operation. By doing so, Flink ensures to record the current state of the Pravega Readers which can be used as a reference (uses Checkpoint id) in it’s checkpointed state.
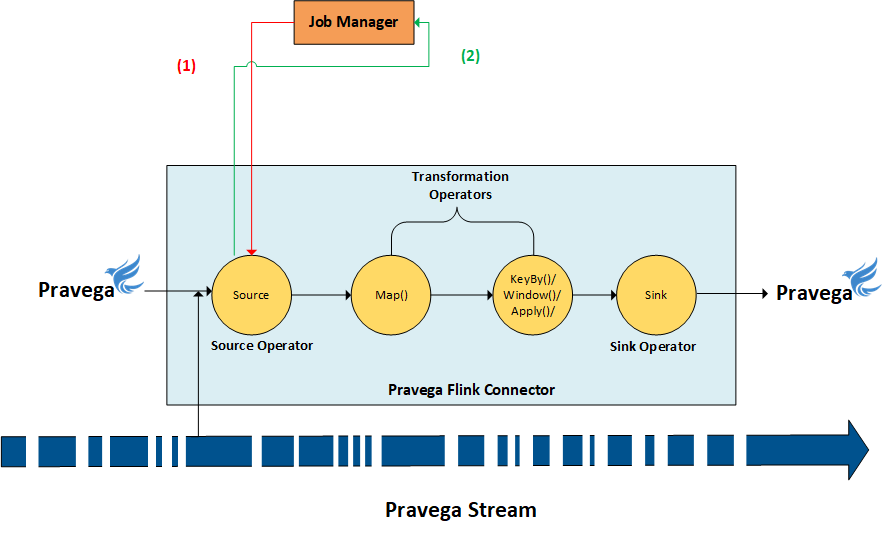
The Job Initialization Phase
- Job Manager requests FlinkPravegaReader to provide Checkpoint hook instance that it could use to initiate the Checkpoint request to Pravega.
- FlinkPravegaReader creates Checkpoint hook instance and initializes it with the Pravega Reader Group instance. FlinkPravegaReader sends the Checkpoint hook instance to the Job Manager.
The above steps were part of the job initialization phase that takes care of registering the checkpoint hook reference for the job manager to effectively coordinate and complete the checkpoint operation with the Source operator.
Illustration of the Checkpoint Request
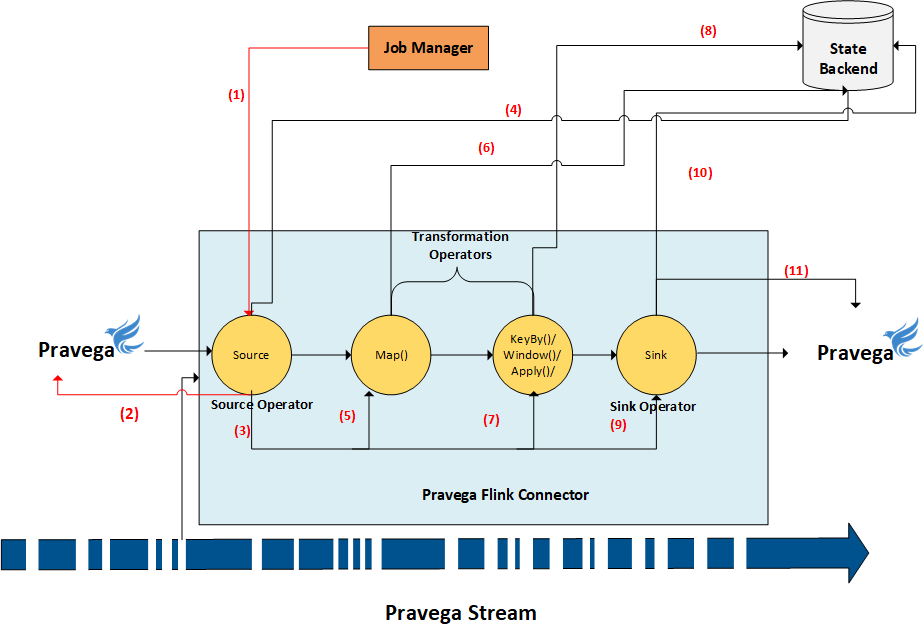
Let’s revisit the “simple Flink streaming application” that we illustrated at the beginning of this section and use it as a basis to explain how the Checkpoint request from the Job Manager is being handled by the FlinkPravegaReader Source operator.
- The Job Manager initiates checkpoint request using the checkpoint hook handle supplied by the FlinkPravegaReader.
- The checkpoint Hook initiates a Checkpoint request to Pravega using the Reader Group instance. Pravega readers coordinate and perform a checkpoint operation (asynchronous operation).
- The FlinkPravegaReader continues to process the events from the Pravega When the Pravega Readers completes the Checkpoint request; it sends a Checkpoint event as part of the event flow to FlinkPravegaReader. Upon receiving the Checkpoint event from Pravega, the FlinkPravegaReader initiates a Checkpoint request using the checkpoint trigger that was provided by the Task Manager instance during the initialization phase.
- The source operator records the checkpoint state (Reader Group Checkpoint reference) in the state backend and advances the barrier to the next downstream operator.
Now let’s see how the barrier makes progress from Source to all the downstream operators, including the Sink.
Step (5), (7) and (9) shows the advancement of the barrier from each operator, and before they advance the barrier, the operator state is persisted in the state backend, i.e., step (6), (8) and (10).
The final stage in the checkpoint operation (step 11) is the sink operator (FlinkPravegaWriter) that interacts with Pravega to initiate the state update.
Sink (FlinkPravegaWriter)
The FlinkPravegaWriter implementation supports both transactional as well as non-transactional Writer options to the user. To help end-to-end exactly-once guarantee for the data pipeline, we need to use the transactional Writer option. When the job is initialized, we begin a transaction such that all the sink operations performed will result in the writes being batched that will be scoped to the open transaction.
In the previous diagram, after the barrier is advanced to the sink operator (FlinkPravegaWriter) step (11) performs a “flush()” API call to the transaction instance which results in ensuring that the writes are persisted. The current transaction instance along with the Checkpoint ID, will be stored in the state backend, after which a new transaction will be opened to accommodate any subsequent writes that are performed after the current checkpoint operation.
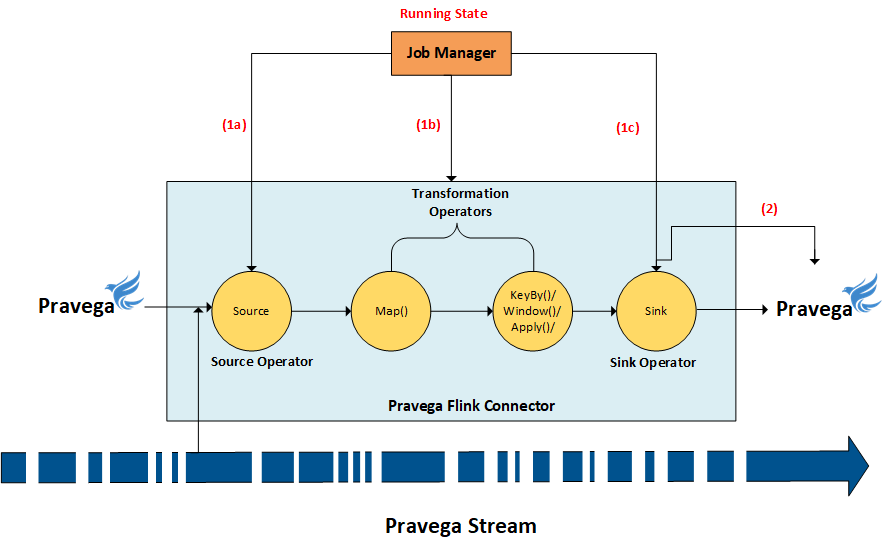
Step (1) to (11) that we have seen above is called the pre-commit phase of the two-phase commit operation. If any of the operators run into an error state during the pre-commit operation, all other requests are aborted, and the checkpoint state will be rolled back to the last successfully completed state.
The next and the final step in the checkpoint process is the commit phase which results in the Job Manager issuing “Notify Checkpoint Complete” request to all the operators (see below diagram step 1a, 1b and, 1c) to perform the final commit. After a successful pre-commit, the commit must be guaranteed to succeed eventually. If a commit fails (for example, due to an intermittent network issue), the entire Flink application fails, the application restarts according to the restart strategy configuration defined in the Flink job which results in another commit attempt. This process is critical because data loss occurs if the commit does not eventually succeed.
FlinkPravegaWriter, upon receiving the “Notify Checkpoint Complete” request will look-up the Transaction associated with the corresponding Checkpoint ID and performs a “commit()” API call to Pravega to finalize the Transaction (which results in appending all the events written to the Transaction into the stream).
Code Reference
The connector implementation for both reader and writer provides an easy to use fluent style API to create reader and writer instances for performing read and write operations.
Here is a code snippet that shows a sample Flink job that uses Pravega as a source and sink.
There are many sample applications that are available in Pravega Samples repository that can be referenced to understand further and explore the usage of Flink Pravega connectors.
Wrapping Up
In this post, we have seen how Flink Pravega Connector can be used to build an end-to-end streaming application with the exactly-once guarantee. The connector makes use of
- Flink’s checkpointing mechanism to snapshot the application state which forms the basis for application recovery. It also acts as a foundation to support exactly-once
- Pravega’s Reader and Writer features enable Flink to provide end-to-end exactly-once guarantee using two-phase commit implementation.
Acknowledgments
Thanks to Srikanth Satya and Flavio Junqueira for comments that helped to shape this post. A special note of thanks to Stephan Ewen for his contributions to the Flink Pravega connector project.
About the Author

Vijay Srinivasaraghavan works for DELL EMC and is one of the main contributors of the Flink Pravega Connector project. His current project involves building an enterprise-grade streaming analytics data platform for IoT type of workloads. His interests include products involving large scale data analytics, Big Data, NoSQL, and private cloud infrastructure platforms.
References
[1] A. Spector, Performing Remote Operations Efficiently on a Local Computer Network, CACM, April 1982
[2] https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/state/checkpointing.html
[3] https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html
[4] https://pravega.io/docs/latest/pravega-concepts /
[5] https://pravega.io/docs/latest/reader-group-design/