
Several of the difficulties with tailing a data stream boil down to the dynamics of the source and of the stream processor. For example, if the source increases its production rate in an unplanned manner, then the ingestion system must be able to accommodate such a change. The same happens in the case a processor downstream experiences issues and struggles to keep up with the rate. To be able to accommodate all such variations, it is critical that a system for storing stream data, like Pravega, is sufficiently flexible.
The flexibility of Pravega comes from breaking stream data into segments: append-only sequences of bytes that are organized both sequentially and in parallel to form streams. Segments enable important features, like parallel reads and writes, auto-scaling, and transactions; they are designed to be inexpensive to create and maintain. We can create new segments for a given stream when it needs more parallelism, when it needs to scale, or when it needs to begin a transaction.
The control plane in Pravega is responsible for all the operations that affect the lifecycle of a stream, e.g., create, delete, and scale. The data plane stores and serves the data of segments. The following figure depicts the high-level Pravega architecture with its core components.
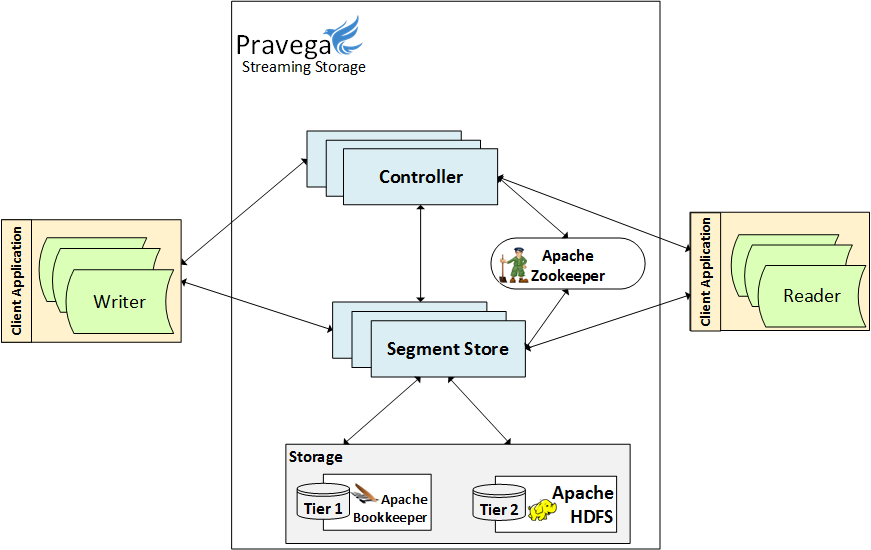
Given that we have discussed concepts of the client in previous blog posts, we focus on the controller and the segment store in the following sections.
Controller
The controller implements the Control Plane of Pravega. It is responsible for some very important tasks in a Pravega cluster, for example:
- Stream lifecycle: Manages the creation, deletion, and scaling of streams.
- Transaction management: It is responsible for beginning or creating a transaction and tracks its state, including the time tracking.
Controller Service
The controller is primarily responsible for orchestrating all stream lifecycle operations, like creating, updating, scaling and deleting a stream. As such, the controller maintains the stream metadata and responds to client queries about streams.
Creating and deleting a stream, are operations triggered by a user request, but there are some operations of the controller that are triggered by internal mechanisms, such as scaling and retention. The controller implements workflows that enable a user to configure the controller to scale a stream automatically and to truncate it based on time or size. The configuration of this mechanism is based on policy, and the policy is configured as part of the stream configuration according to the behavior the application desires. See the following code snippet for an example of how to configure such policies:
Client interactions
The controller plays a vital role in client interactions. Clients interact with the controller to create and delete scopes and streams. This interaction happens via a Java or a REST API.
Creating and deleting a stream are actions triggered directly via API calls, but there are other operations that are critical for the correct operation of the client that is transparent to the application. Specifically, the client during its lifetime needs to interact with the controller to learn about the set of segments, and where they live. Recall that the streams perform auto-scaling, and as such, the set of segments of any stream configure to auto-scale can change over time. As a stream evolves, the client needs to know of such splits and merges of segments, which it obtains from the controller. Knowing the current set of segments is not sufficient, however. The client also needs to know which segment store to contact for a given segment. The controller is responsible for such rendezvous between clients and segment stores.
As part of scaling a stream, the controller is responsible for sealing some of its segments. Sealing segments is the primary mechanism we use to indicate to the client that it needs to go and fetch new metadata from the controller. Upon finding the end of a segment (segment sealed), the client requests successor segments from the controller, including the information it requires to contact the appropriate segment stores for the new segments. This flow is critical to ensure that the scaling of a stream happens seamlessly to the application, avoiding any disruption to the application.
Controller Instances
The controller service comprises a number of controller instances, and those instances currently rely on Apache ZooKeeper for metadata coordination. The number of instances can be created based on the cluster requirements. A minimum of two instances is recommended to be able to tolerate crashes, and introduce additional instances, both higher tolerance to crashes and to increase the capacity. Whenever possible, the controller caches ZooKeeper metadata to avoid the network latency.
As the number of controller instances changes over time, the system must be able to accommodate changes to the set of controllers. In the case a controller instance crashes or is intentionally removed from the system, we have implemented a failover mechanism such that the remaining instances take over the work of the removed instance. To enable such a failover process, the controller instances register with ZooKeeper and watch for changes to the subscription. Upon detecting that an instance has been removed, each controller instance triggers a set of sweeper tasks to compete for ownership of the work of the removed instance. In this way, we automatically react to the changes in the number of instances in the control plane. Note that the metadata is stored and coordinated via ZooKeeper, and as such, the controller instances are treated as stateless processes. There is ongoing work on moving some stream metadata out of ZooKeeper fort scalability. We will cover it in a future post.
Transaction Management
The controller service manages the lifecycle of transactions. The writers in a user application request the controller to perform all control plane actions concerning transactions. When beginning a transaction, a writer needs to set it up with the controller service. The controller adds necessary metadata to track the state of the transaction and times it out in the case it takes more time to complete.
A client executes a transaction against a single stream as Pravega currently does not support transactions spanning multiple streams. When a client begins a transaction, the controller creates transaction segments, one for each open segment of the stream. For example, say that a client begins a transaction against a stream S that has three open segments s1, s2, s3. The controller creates a transaction tsi for every open segment si, i ∈ {1, 2, 3}. When the client writes an event with a given key k that is to be appended to segment si, the event is appended to tsi. In the case the transaction is committed, the transaction segments are merged onto the stream segments, and the transaction events become available for reading.
Once the writer is ready, it either commits or aborts the transaction according to the application logic, and the controller is responsible for commanding the segment store to perform the merge of the transaction segments. It is also responsible for updating the transaction metadata accordingly.
When ending a transaction by either committing or aborting it, the controller needs to guarantee that the result of the transaction does not change later, once it acknowledges the operation. Accepting to commit a transaction and later aborting the same transaction, or the other way around, are not acceptable scenarios. When it receives a request to commit a transaction, the controller checks the state of the transaction by reading the transaction metadata (stored in ZooKeeper). If the transaction is still open, then the controller updates the metadata to reflect its new state. Note that there can be multiple controller instances, and the update to the metadata needs to be conditional on the znode version to avoid inconsistencies due to a race condition.
Once the transaction metadata operation succeeds, it posts an event to an internal commit stream to be processed asynchronously. Such a stream is a regular Pravega stream used for internal purposes. The events of the internal stream are processed by commit event processors, which are elements in a controller instance that process stream events. Committing the transaction event consists of merging transaction segments. In the case the processing of a commit event is interrupted, e.g., because the controller instance crashed, a commit processor in a different controller stream can pick it up and execute it. Merge operations are idempotent and do not cause any inconsistency when attempted multiple times over the same segments.
Likewise, in the case the transaction aborts, the process is similar for deleting the transaction segments.
For concurrent transactions over the same stream, the controller commits them serially to guarantee the property that the events of two or more transactions are not ordered differently in a single segment. If the controller were to merge two transactions t1 and t2 concurrently, then some segments might order t1 events before t2 events while other segments might have the opposite order. The serial order of commits (and merges) guarantees that this property is satisfied.
One interesting aspect is the handling of transactions in the presence of scaling. If there is a one-to-one mapping between transactions segments and open stream segments, then what happens when the stream scales and changes the number of segments? In the original design of Pravega, we had opted for blocking the scaling of the stream until all outstanding transactions committed or aborted. We had a timeout that would abort the transactions in the case they took too long to make a call while a scaling operation was in progress. The main problem this time-out could cause is that an application took too long to commit a transaction even though it did want to commit it. This situation has, in essence, a correctness issue because the written data was taken from the application while the application was counting on exposing it. Recently, we added a feature that enables transactions to “roll” across scaling events. In the case a transaction starts with a given set of segments and the set of segments is different when the transaction commits, we process it like a scaling of the stream: we seal the current set of segments Σ, make the transaction segments the successors, and create a new set of successor segments Σ’ such that | Σ | = | Σ’ | and the split of the key space is the same as in Σ.
Segment store
The segment store implements the data plane of Pravega and does exactly what the name says: it stores segments. It plays a critical role in making segment data durable and serving it efficiently. The segment store is agnostic to the concept of streams. The composition of segments into the stream abstraction is performed by the controller. For example, when we split up a segment into new ones, the segment store creates the new segments, but it is the responsibility of the controller to make sense of the order of segments in the stream.
One of the roles of the segment store service is to merge transaction segments into segments of a stream. The controller is responsible for commanding the segment store to merge transaction segments upon transaction commits, and the segment store executes the necessary operations on a per segment basis.
The segment store has two primary storage dependencies, which we give the generic names of Tier 1 and Tier 2. The primary goal of Tier 1 is to guarantee that writes are durable with low latency. Making a write durable means that once the application learns that the request to write has succeeded, the system guarantees that the written is not lost despite faults. The implementation of Tier 1 is an append-only data structure that the segment store writes to. Think of it as a journal for the updates to the segment store.
We log synchronously to Tier 1 the appended data and some other bookkeeping data that we need to persist for the correct operation of the service. Currently, Pravega uses Apache BookKeeper [1] to implement Tier 1. BookKeeper provides excellent write latency for short amounts of data, which guarantees the durability of writes while providing low latency for streams of events. We also use the ability of fencing a BookKeeper ledger when opening it to fence out stale writers. That is a feature that BookKeeper offers that enables consistency despite false crash suspicions.
We asynchronously migrate data to Tier 2, and once we do it, we truncate the corresponding data from Tier 1. We have a Tier 2 for a couple of reasons:
- We envision a system that can store an unbounded amount of data for a large number of segments. Consequently, we need a horizontally-scalable bulk store to accommodate all this data, following more closely existing options for cloud storage.
- We need to provide a high throughput option for reading data, especially when reading older data when we need to catch up with the stream.
We currently support a few options for Tier 2: HDFS [2], NFS [3], and Extended S3 [4].
At this point, it is important to talk about the two different kinds of reads we anticipate so that we understand the motivation behind this architecture. We expect applications to perform tail reads and catch-up or historical reads [5]. Tail reads correspond to reading bytes that have been recently written, pretty much tailing the writers of the stream as the term indicates. Such readers expect very low latency, and to satisfy this requirement, we keep a cache of data recently written in memory to serve these reads. We currently use RocksDB [6] to implement such a cache.
The following figure illustrates tail and catch-up reads in Pravega. All data the segment store serves is from the cache. For tail reads, the expectation is that it is fresh enough so that it is a cache hit and can be served immediately. For historical data, it is likely to be a cache miss, in which it induces a read to Tier 2 to populate the cache.
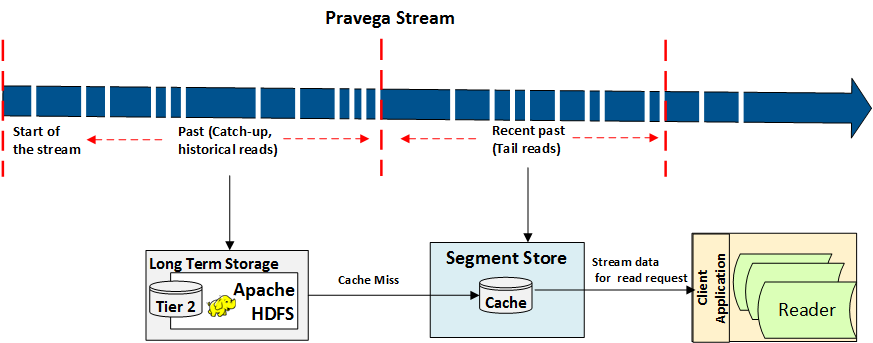
The data in Tier 1 is used uniquely for recovery, and as we have discussed above, we serve reads from cache and fetch data from Tier 2 in the case of a cache miss. We have additionally started the implementation of a different kind of segment store that is read-only (PDP-25). The read-only segment store does not cache the data coming out of Tier 2. Such a feature is useful for settings with a high volume of batch reads (e.g., for batch jobs), as such batch reads might end up interfering with the ingestion of new data in the case of the regular segment store. The work of the read-only segment store is not yet complete, and the feature is not available at the client at the time of this writing.
The workload in a segment store server is split across segment containers. This is not to be confused with containers in the context of lightweight virtualization (e.g., Docker containers). Segment container is a concept of Pravega. They are a logical grouping of segments and are responsible for all operations on those segments within their span. The container is the unit of work assignment and recovery; the controller is the element responsible for assigning containers to the distinct segment stores upon rebalancing due to a new segment store starting or redistribution due to a segment store crashing. Each container is expected to have a single owner at any time, and we use fencing to prevent problems with zombie processes (old owners that still think they own it).
Each instance of the segment store executes a container manager, which is responsible for managing the lifecycle of the segment containers that are assigned to that instance. In the case a container is reassigned, the container manager needs to react by either shutting down or bootstrapping the segment container, depending on whether the segment store instance is the new owner or the previous owner of the container.
Wrapping up
This post covered a high-level view of the internals of Pravega. It presented the controller and the segment store. They are together the two main components implementing the core of Pravega: the controller implements the control plane, while the segment store implements the data plane. As discussed in previous posts, the segment abstraction is very important to enable flexibility in the development of kick-ass features to support stream as storage primitive.
Future posts will cover controller and segment store mechanisms in detail, and this post serves as an introduction of concepts to give the reader context for upcoming, in-depth posts.
Acknowledgements
Thanks to Srikanth Satya and Shivesh Ranjan for the comments, that helped to shape this post.
About the Author

Flavio Junqueira leads the Pravega team at Dell EMC. He holds a PhD in computer science from the University of California, San Diego and is interested in various aspects of distributed systems, including distributed algorithms, concurrency, and scalability. Previously, Flavio held a software engineer position with Confluent and research positions with Yahoo! Research and Microsoft Research. Flavio has contributed to a few important open-source projects. Most of his current contributions are to the Pravega open-source project, and previously he contributed and started Apache projects such as Apache ZooKeeper and Apache BookKeeper. Flavio coauthored the O’Reilly ZooKeeper: Distributed process coordination book.
References
[1] Apache BookKeeper. http://bookkeeper.apache.org
[2] Hadoop File System. https://hadoop.apache.org/
[3] R. Sandberg, D. Goldberg, S. Kleiman, D. Walsh, and B. Lyon. Design and Implementation of the Sun Network Filesystem. USENIX Conference and Exhibition, 1985.
[4] Extended S3. https://www.emc.com/techpubs/ecs/ecs_s3_supported_features-1.htm
[5] Leigh Stewart. Building DistributedLog: High-performance replicated log service, September 2016.
[6] RocksDB: A persistent key-value store for fast storage environments. https://rocksdb.org/
[7] Stephan Ewen and Flavio Junqueira, An elastic batch and stream processing stack with Pravega and Apache Flink, April 2018.
Technical publications by Aparna