

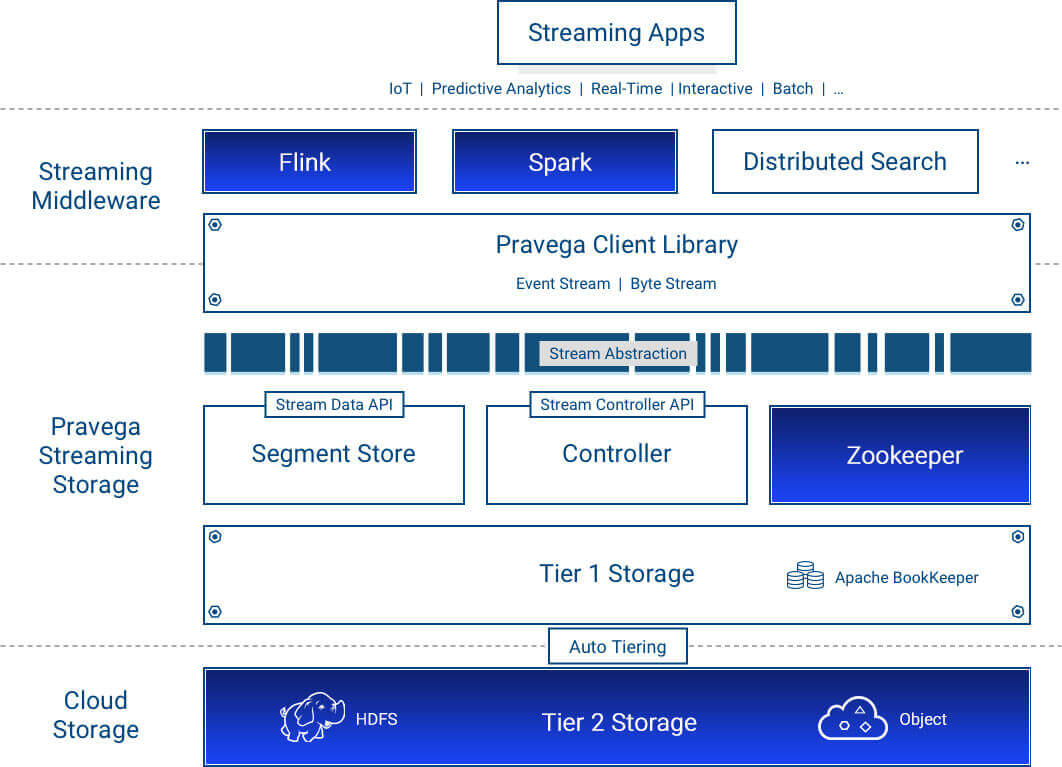
Streaming is motivating us to rethink fundamental data processing and storage principles. As storage experts, Dell EMC is doing its part by designing a new storage primitive purpose-built for streaming data. We are open sourcing Pravega under the Apache 2.0 License to accelerate the adoption of streaming technology. Open source is right for Pravega because we believe that disruptive technologies should be owned and driven by a community of passionate open source developers.
Exactly-Once Semantics
Ensure that each event is delivered and processed exactly once, with exact ordering guarantees, despite failures in clients, servers or the network.
Auto-Scaling
Unlike systems with static partitioning, Pravega can automatically scale individual data streams to accommodate changes in data ingestion rate.
Distributed Computing Primitive
Pravega is great for distributed computing; it can be used as a data storage mechanism, for messaging between processes and for other distributed computing services such as leader election.
Write Efficiency
Pravega shrinks write latency to milliseconds, and seamlessly scales to handle high throughput reads and writes from thousands of concurrent clients, making it ideal for IoT and other time sensitive applications.
Unlimited Retention
Ingest, process and retain data in streams forever. Use same paradigm to access both real-time and historical events stored in Pravega.
Storage Efficiency
Use Pravega to build pipelines of data processing, combining batch, real-time and other applications without duplicating data for every step of the pipeline.
Durability
Don't compromise between performance, durability and consistency. Pravega persists and protects data before the write operation is acknowledged to the client.
Transaction Support
A developer uses a Pravega Transaction to ensure that a set of events are written to a stream atomically.

Change Data Capture (CDC) is becoming a popular technique for interconnecting disparate systems, for replicating state across traditional boundaries, for decomposing existing monoliths into microservices, and for the recordation of audit trails. CDC is the idea of emitting a changelog of all INSERT‘s, UPDATE‘s, DELETE‘s, and schema changes performed on a database. Debezium.io is an […]

