
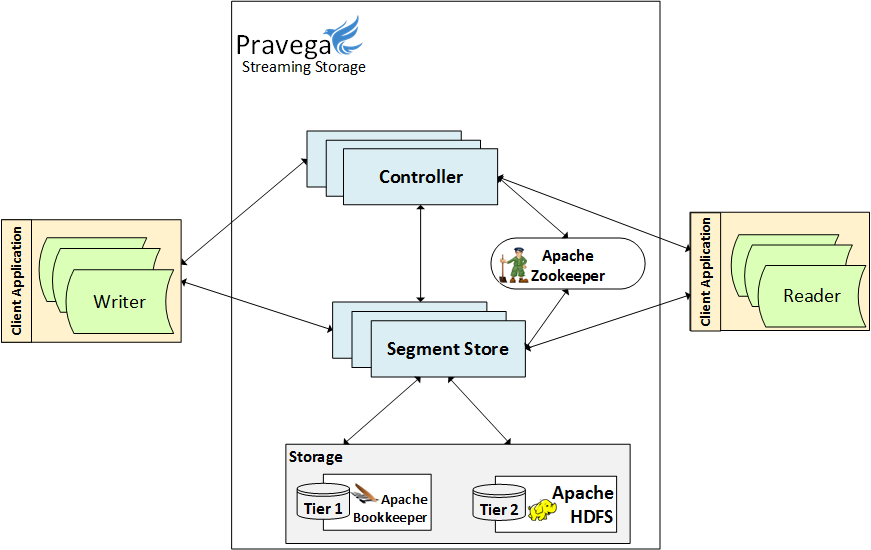
The Pravega Segment Store Service is a subsystem that lies at the heart of the entire Pravega deployment. It is the main access point for managing Stream Segments, providing the ability to modify and read their contents. The Pravega Client communicates with the Pravega Stream Controller to identify which Segments need to be used (for a Stream), and both the Stream Controller and the Client deal with the Segment Store Service to operate on them.
We’ll be exploring the functionality involved in the internal workings of the Segment Store, covering its components, how they interact and, in future posts, we will be doing deeper dives into each of them, explaining how they work.
Recap: Pravega Internals
Before we begin, let’s have another look at the big picture of Pravega. For a more detailed explanation, refer to our previous post (Pravega Internals). A Pravega cluster is made of the following:
- Client: Interfaces with all Pravega components – this is the user’s way of communicating with Pravega.
- Controller: Handles all control operations involving stream lifecycle and transaction management.
- Segment Store: Deals with all data plane operations (append, read) and stream segment management.
- Tier 1 Storage: A log-based storage system which the Segment Store uses to record all changes made to segments.
- Pravega currently uses Apache Bookkeeper for Tier 1, but other implementations are possible as well.
- Tier 2 Storage: A storage system that can store large amounts of data long term, providing good read/write throughput.
- Out of the box, Pravega supports HDFS, NFS, and ExtendedS3, though other implementations are possible as well.
- Apache Zookeeper is used for leader election and general cluster management.
Why a Segment Store?
One of the first questions that come to mind is why add a Segment Store in the first place. Why not follow a simpler, more intuitive approach where the Client communicates directly with Tier 2 for writing and reading data? Since adding an extra hop on the ingestion path has the potential of reducing performance, how can the Segment Store enable Pravega to achieve better performance with the same guarantees as opposed from using a simpler, more direct architecture?
To answer this, let’s take a small step back and look at some of the core features Pravega offers.
Typical storage systems are optimized for ingesting data at high throughputs with a relatively high initial latency for each request. This doesn’t bode well for IoT scenarios, where each event is rather small. Buffering data writer-side may help with this, but it is not an option for many implementations due to resource constraints and the fact that the system needs to react in real time to such events, which is not possible if they are still in the writer’s buffer. We want each event to be published as soon as it is generated with as little delay as possible.
Ensuring that events are not lost in the system or not delivered multiple times is an effort that requires proper synchronization on both the write and read sides. When committing an event, Writers need to make sure it has been stored, and if so, ensure it will not be written multiple times. To enable that, they use attribute-conditional appends when writing to Segments (each writer keeps track of its position and atomically verifies and updates it with each append). On the other side of the spectrum, Readers need to ensure that events in a Stream are not skipped over and not processed more than once. They use the State Synchronizer, which makes offset-conditional appends to a dedicated, internal segment to provide such a service.
Transactions make heavy use of Segment concatenation, while Stream Retention needs to trim Segments from the beginning while preserving the remaining offsets. On top of that, multiple Writers need to be able to write to the same Segment at the same time without corrupting each other’s data.
Each storage system out there, whether open or closed source, provides one or more of the necessary primitives that would enable Pravega to operate directly on them. However, no storage system implements all that is needed. Some have support for offset-conditional appends, and some have rich attribute support; some allow multiple concurrent writes while some enforce a single-writer paradigm; none support head truncation and only a few have native support for concatenation. Pravega does need a dedicated data plane component that enables it to offer all the functionality it advertises. This component is called the Segment Store.
Pravega Segment Store Service
The Segment Store manages Segments – ordered sequences of bytes that implement append-only write semantics and where each byte is addressable via its offset. Segments are similar to ordinary files in any file system, except that their contents are immutable once written.
Before diving in, it’s important to highlight a few design considerations relating to guarantees that the Segment Store has to offer. Together, these form the guiding principles that drove every single design decision that lead to the current architecture.
Pravega seamlessly tiers data between log-based storage (Tier 1) and long-term storage (Tier 2). The upstream layers (Client and whoever is using it) do not need to know where the data at a particular Segment offset resides. Internally it may exist only in Tier 1, or it may have already been moved to Tier 2. It may even be cached. By providing data tiering transparency, the Segment Store can significantly simplify the design of the Client and user interactions.
An operation that changes a Segment (append, seal, truncate, merge, etc.) is only acknowledged after it has been persisted and replicated to Tier 1. Durability ensures that there is no scenario when the Segment Store acknowledges an operation but lost the data due to a crash.
Furthermore, once an operation is acknowledged, it needs to be applied exactly once. Operations are processed in the order in which they are received and are also applied to Tier 2 in the same order. This holds true even in the case of a crash followed by a recovery. On the read side, once a particular value has been read at a specific offset, the same value will always be read at that offset. Collectively, these are known as write and read consistency.
Any online service needs to adjust to varying workloads and take advantage of more machines if provided. Consequently, availability should not be affected due to host machines going offline. The Segment Store needs to scale horizontally and divide work uniformly across the Pravega cluster. There are various approaches to scalability. A stateless service behind a load balancer is the most trivial approach. However, this would require us to fetch the state of each segment for any operation that we execute and persist it after completion. Such an approach would also prevent us from implementing concurrency and would be a significant drag on performance. An enhancement is to make Segments stick to particular Segment Store instances, enabling us to keep the state in memory for multiple operations and enable seamless processing. The drawback for such an approach is that, over time, segments will be unevenly distributed among hosts; this is because the mapping of such segments to machines cannot change once machines are added to or removed from the cluster.
To alleviate this problem, we introduce an indirection, namely Segment Containers. We can define a much larger number of Segment Containers than there are nodes in the cluster, and we map Segments to Segment Containers, which are hosted by Segment Store instances and preserve state for those Segments mapped to them. Each Segment belongs to exactly one Segment Container, and a Segment Container is responsible for all operations on its owned Segments. With this approach, it is much easier to reallocate load across the cluster for any scalability event that includes nodes joining or exiting the cluster.
Segment Containers
As described in the section Segment store in the previous blog, Segment Containers are the components that do the heavy lifting on Segments, and the sole role of Segment Store processes is to host these Containers. Segments are mapped to Segment Containers using a fixed, uniform hash function that is known by the Controller.
Segment Containers expose the same API as the Segment Store; the latter delegates the incoming request to the appropriate container instance. Inside the Segment Store, requests either modify the state of a Segment or fetch data from it. Every request that modifies the state of a segment is transformed into an Operation and queued up for processing. There are other, internal types of Operations which are handled similarly.
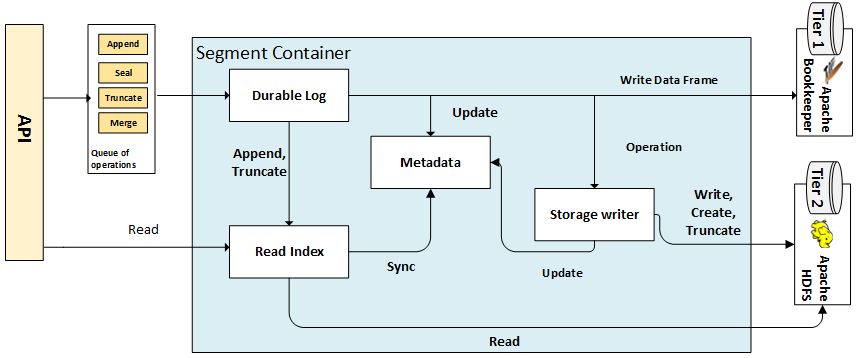
Processing Operations
The Durable Log performs all the heavy lifting when it comes to accepting and processing new Operations and executing a crash recovery. The Durable Log sits at the core of each Segment Container. It ingests Operations, validates them, batches them together into Data Frames which are then written to Tier 1, and also makes them available for the Storage Writer so that they may be applied to Tier 2. When any Segment Container crashes or is moved to another host, the Durable Log also performs a seamless recovery and restores its state; all other components do considerably less (if any) recovery-related work.
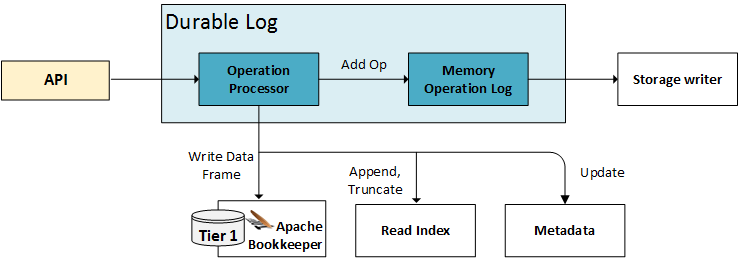
When a new operation is processed, it is immediately sent to the Operation Processor. As we will see in the next installment, the Operation Processor’s responsibility is (as its name implies) to process new operations, persist them to Tier 1 and make their effects reflected in the in-memory Read Index and Metadata. Once the Operation Processor has acknowledged the processing of an operation, the Operation is added to the Memory Operation Log (a simple linked list containing all operations in order).
The Durable Log makes two very important guarantees:
- Operations will be processed in the order they were supplied.
- Acknowledging an operation implies that all non-rejected operations up to, and including it, have all been successfully processed and durably persisted.
- An operation can be rejected if it doesn’t satisfy its preconditions (i.e., conditional append/update failure or modifying a sealed segment).
- Once accepted, an operation can only fail to commit if there is an unrecoverable problem with the underlying Tier 1 layer.
These guarantees are critical for the good operation of the Segment Store. In-order processing of operations enables write-read consistency, while in-order acknowledgment only after persistence enables durability.
Tiering to Long-Term Storage
The Durable Log can be viewed as a write-ahead log where we multiplex writes from multiple Segments. Due to its append-only nature, it is very efficient for writes but not very efficient for accessing data within it. It may also be limited in capacity, as generally, we would like to run this on dedicated fast disks, such as SSDs, making it an expensive choice should a lot of data need to be ingested. As such, we need another component whose purpose is to get the operations queued up in the Durable Log, apply them to Tier 2 (long-term storage) and then trim the Tier 1/Durable Log as needed. This component is called the Storage Writer.
In a nutshell, the Storage Writer de-multiplexes the operations from the Durable Log, groups them by the affected Segment(s), and applies them to those Segments’ representations in Tier 2. It performs several optimizations along the way to maximize throughput, such as buffering smaller appends into larger writes, and others. We will cover the Storage Writer in great detail in a future post, where we will explain, our approach to data tiering.
Reading Data
Up until now, we have discussed the write path: how do we get external modification requests, such as appends, into our system and then finally into Tier 2 and read. The Read Index is an essential component of the Segment Container that provides a transparent view of all the data in a Segment, both from Tier 1 and Tier 2, without the external caller having to know where such data resides.
The Read Index is backed by a local disk-spillable cache, which in our case is implemented by RocksDB. This cache stores data for those Segment ranges that exist in Tier 1 but have not yet been applied to Tier 2 as well as recently made reads that resulted in Tier 2 reads. The Read Index will buffer more data than requested, in anticipation that it will result in a cache hit for a subsequent call (most reads happen in sequential order).
An important feature of the Read Index is the ability to serve Future Reads (also known as Tail Reads). These are reads that have been requested for data that have not been written yet (i.e., at an offset beyond the last offset of a Segment). A Client uses this feature when it needs to tail a Stream; it gets notified of new Events that are written as soon as they are durably stored.
Interaction with the Controller
The Segment Containers are unaware of the presence of the Controller. They are simple services running inside the Segment Store process. The Segment Store is running an additional service, named Segment Container Manager, which interacts with the Controller using . The Controller decides where each Segment Container should run, and it updates certain Zookeeper nodes based on those decisions. The Segment Container Manager watches those Zookeeper nodes and reacts to changes made to the node associated with the owning Segment Store process. As such, it may stop currently running Segment Containers, or it may start ones which aren’t currently running. Inside Pravega, we use Zookeeper strictly for cluster management. All Stream and Stream Segment metadata is stored in specialized Segments hosted by Pravega itself (more on this in a later post).
The Segment Container Manager also watches over the Segment Container it manages; if one of them unexpectedly shuts down (because it detected an error), it checks back with the Controller, and if that Segment Container is still assigned to the same process, it restarts it. In some cases, the best approach for a Segment Container when it detects an error is to restart and not attempt to address it on the fly. Most of the time such errors are cleared and fully recovered from upon a restart (i.e., a transient Tier 1 error). Those errors that cannot be addressed via a Segment Container recovery will end up putting it into an Offline mode – it is up and running, but it won’t respond to requests until the underlying issue has been resolved. Such situations are extremely unlikely to happen, but in case they do, the Segment Container and its sub-components will stop processing more requests to prevent the problem from getting worse.
Internal API
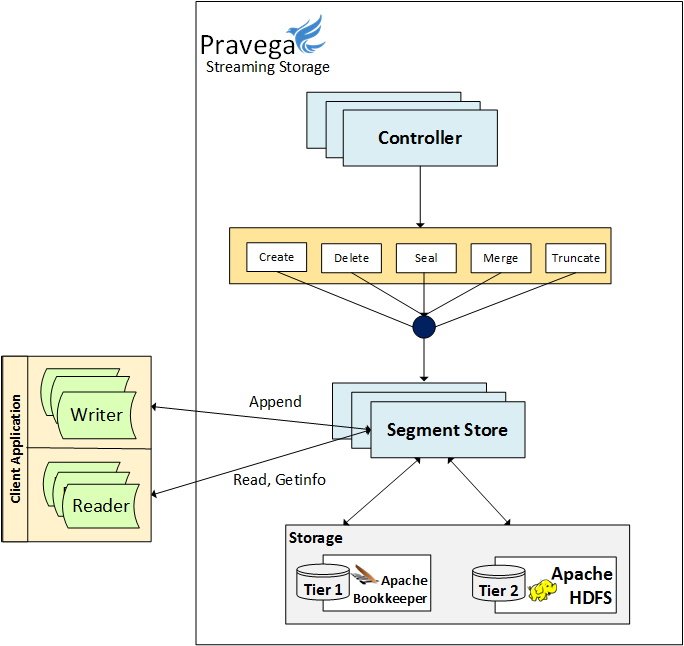
In Pravega, we have based our internal Segment Store API on a typical file API, with the appropriate adjustments that reflect their append-only nature. The API can be broken down in two groups:
- Control plane API
- This is invoked by the Controller, and not as a direct action of a user call.
- Allows creating, sealing, merging, truncating or deleting Segments.
- Data plane API
- This is invoked as a direct result of a user action via the Client – these are usually on the critical path for the EventStreamWriter or EventStreamReader
- Allows appending new data, reading existing (or future) data and updating attributes.
- Appends can be unconditional, offset-conditional or attribute-conditional. While not exposed via the Client’s Stream API (EventStreamWriter) these different types of conditional appends are crucial in enforcing the exactly once delivery guarantee of Pravega.
- Reads can be direct (requested byte range is available) or tail (when the read offset is beyond the last offset of the Segment).
Wrapping up
In this post, we took a first look at how the Segment Store is organized internally and how data flows inside it. We briefly went over each major component and explained their roles.
In future posts, we will be doing deeper dives into every component of the Segment Store. We will examine how we can achieve good performance using operation pipelining and write parallelization, shed more light on the intricate details of moving data to Tier 2, as well as how reads are executed.
Acknowledgments
Thanks to Srikanth Satya and Flavio Junqueira for the comments that helped to shape this post.
About the Author

Andrei Paduroiu is among the original group of developers who started the Pravega project and is currently a core contributor, owning the data plane server-side aspects of it – the Segment Store. He holds a MS Degree from Northeastern University and a BS Degree from Worcester Polytechnic Institute. Previously, Andrei held a software engineering position with Microsoft and Vistaprint. Andrei’s interests include distributed systems, search engines, and machine learning.